Hive has come a long way in the past couple of years – especially due to the Stinger Initiative that culminated in Hive 0.13 which is already available in some of the leading Hadoop Distribution Components & Versions. As the pretty picture below showshows, the Hive community hasn't stopped there and has publicly declared, yet another, three-release initiative called (awesomely enough!) Stinger.next.
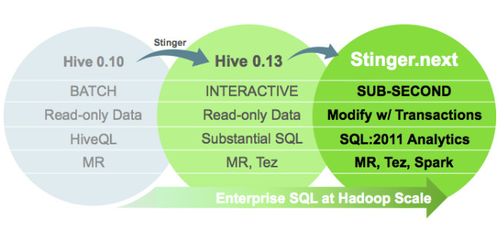
The Hortonworks Labs page for Stinger gives a bit of a breakdown and a timeline of what to expect in, and delivery dates for, the now-expected three releases in for a major initiative in the Hive space. As you can see from that last link, there are plenty more performance goodies coming our way over the rest of 2014 and through 2015.
If you're wondering about Stinger.NOW (™ by yours truly!), they then don't fret, there are still plenty of option of how to tune and improve options for tuning and improving performance with all the great things that Stinger gave us. In fact, much of the options we available have have been there quite a while. The following is a prioritized list of resources I'd suggest using to explore options that are available to younow.
- Interactive Query for Hadoop with Apache Hive on Apache Tez (Hortonworks)
- 10 Best Practices for Apache Hive (Qubole)
- 5 Tips for efficient Hive queries (Qubole)
- Tuning for Interactive and Batch Queries (Hortonworks)
- and... of course... emergent (ever since I published my enterprise 2.0 book review (using web 2.0 technologies within organizations) I can't stop using that word!!) grass-roots efforts such as Hive SQL Best Practices (David Streever)
You're probably thinking, great, Lester just gave me a list of links and didn't supply any special sauce of his own. To keep you from moaning any further, here's my prioritized list of things to focus on when trying to make gain performance improvements with Hive.
- Use ORC file format and Tez as the execution engine
- Partition your tables
- Denormalize data (when it makes sense)
- Utilize bucketing for join issues when join keys are common (and usually only when there is a "whole bunch" of them)
- Issue parallel execution "hints"
- Enable vectorization and leverage "explain" plans
- Review "persistent queues" (i.e. that last Hortonworks link above) against your use cases for applicability and potential value add
Do note that this the elements from the list above can be used piecemeal. Your specific use case and data (via exploration and testing, of course!) will drive which of these actions are going to work best for you. And, as always, Happy Hadooping!