how do i load a fixed-width formatted file into hive? (with a little help from pig)
UPDATE: Feb 5, 2015
See the comments section which identifies a better way to do this using FixedWidthLoader.
I was talking with a client earlier this week that is using the Hortonworks Sandbox to jumpstart his Hadoop learning (hey, that's exactly why we put it out there).
![]() Thanks to all the Sandbox tutorials out there he already knew how to take a delimited file, get it into HDFS, use HCatalog to build a table, and then run Hive queries against it. What he didn't know how to do was to load up a good old-fashioned fixed-width formatted file into a table. My first hunch was to use a simple Pig script to convert it into a delimited file and I told him I'd pull together a simple set of instructions to help him with his Sandbox self-training. Robert, here ya go!!
Thanks to all the Sandbox tutorials out there he already knew how to take a delimited file, get it into HDFS, use HCatalog to build a table, and then run Hive queries against it. What he didn't know how to do was to load up a good old-fashioned fixed-width formatted file into a table. My first hunch was to use a simple Pig script to convert it into a delimited file and I told him I'd pull together a simple set of instructions to help him with his Sandbox self-training. Robert, here ya go!!
Create & Upload a Test File
To try this all out we first need a little test file. Create a file called emps-fixed.txt on your workstation with the following contents (yes... the first two lines are part of the exploration, but they don't break anything either).
12345678901234567890123456789012345678901234567890123456789012345678901234567890 EMP-ID FIRST-NAME LASTNAME JOB-TITLE MGR-EMP-ID 12301 Johnny Begood Programmer 12306 12302 Ainta Listening Programmer 12306 12303 Neva Mind Architect 12306 12304 Joseph Blow Tester 12308 12305 Sallie Mae Programmer 12306 12306 Bilbo Baggins Development Manager 12307 12307 Nuther One Director 11111 12308 Yeta Notherone Testing Manager 12307 12309 Evenmore Dumbnames Senior Architect 12307 12310 Last Sillyname Senior Tester 12308
Then upload the file into HDFS and just land it in your home directory on the Sandbox.
I'm taking some creative liberty and assuming that you've worked through (or at least understand the concepts of) some/most/all of the Sandbox tutorials. For example, check out Tutorial 1 to see how to upload this file. If at any point in this blog posting you are unfamiliar with how to do an activity, check back with the tutorials for help. If you can't find which one can help you, let me know in the comments section and I'll reply with more info.
At this point, you should have a /user/hue/emps-fixed.txt file sitting in HDFS.
Build a Converter Script
Now we just need to build a simple converter script. There are plenty of good resources out there on Pig including the tutorials; I'm even trying to build up a Pig Cheat Sheet. For the one you'll see below, I basically stripped down the info found at https://bluewatersql.wordpress.com/2013/04/17/shakin-bacon-using-pig-to-process-data/ (remember, a lazy programmer is a good programmer & imitation is the sincerest form of flattery) which is worth checking out.
Using the Sandbox lets create a Pig script called convert-emp which will start out with some plumbing. Yes, that base "library" is called the piggy bank – I love the name, too!!
REGISTER piggybank.jar; define SUBSTRING org.apache.pig.piggybank.evaluation.string.SUBSTRING(); fixed_length_input = load '/user/hue/emps-fixed.txt' as (row:chararray);
Then build a structure using the SUBSTRING function to pluck the right values out of each line. Lastly, just write this new structure into a file on HDFS.
employees = foreach fixed_length_input generate
(int)TRIM(SUBSTRING(row, 0, 9)) AS emp_id,
TRIM(SUBSTRING(row, 10, 29)) AS first_name,
TRIM(SUBSTRING(row, 30, 49)) AS last_name,
TRIM(SUBSTRING(row, 50, 69)) AS job_title,
(int)TRIM(SUBSTRING(row, 70, 79)) AS mgr_emp_id;
store employees into '/user/hue/emps-delimited';
Verify the Output File
Now you can navigate into /user/hue/emps-delimited on HDFS and you'll see the familiar (or not so familiar?) "part" file via the Sandbox's File Browser which shows the following tab-delimited content.
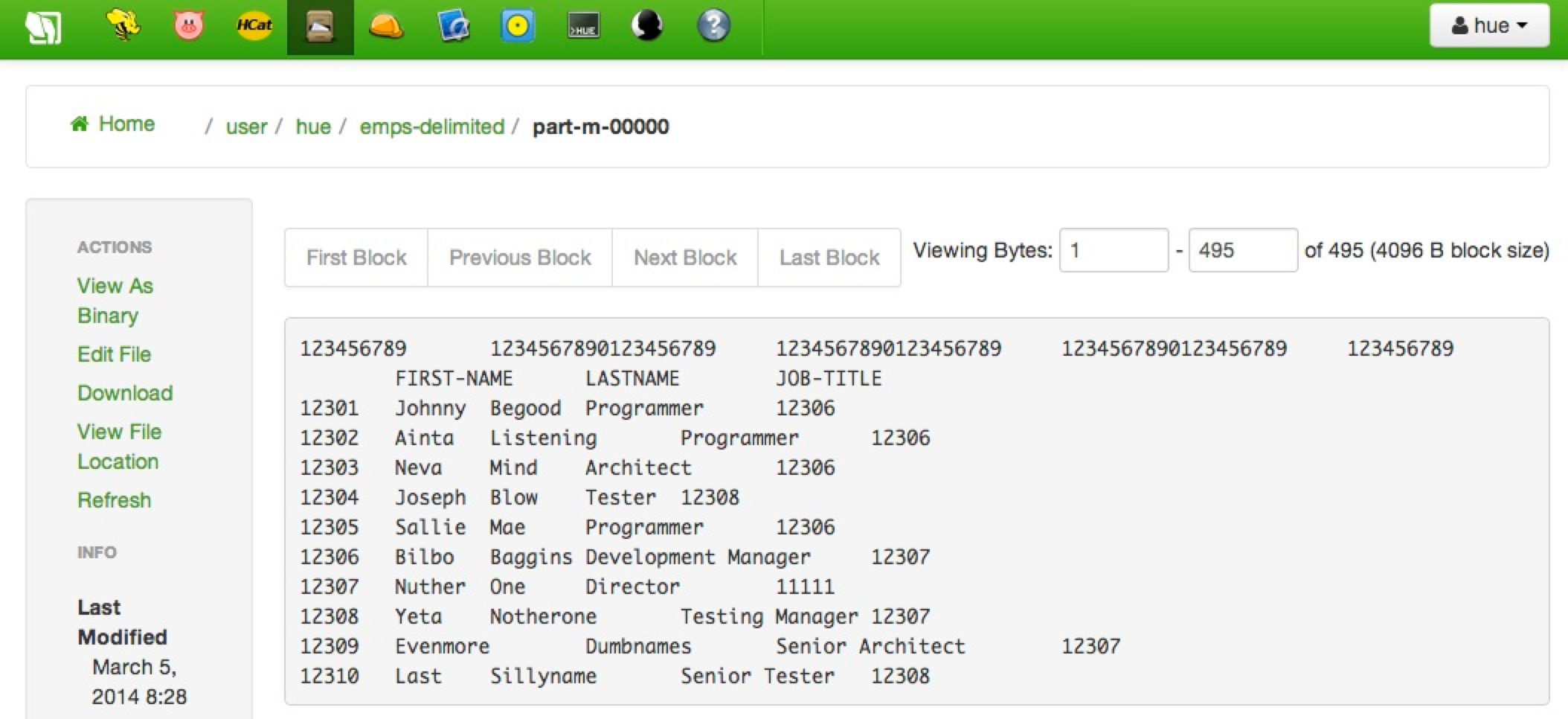
You're welcome to rerun the exercise without the first two rows, but again, they won't cause any real harm due to the forgiving nature of Pig who tries its best to do what you tell it to do. For the "real world", you'd probably want to write some validation logic to make sure things like the value "EMP-ID" (from the source file) fails miserable when trying to be cast to an integer.
Load a Table and Run a Query
Now you need to create a table based on this delimited file (hint, see Tutorial 1 again for one way to do that) and then run a simple query to verify all works. I ran the following HiveQL.
select emp_id, last_name, job_title from employees where mgr_emp_id = 12306;
It returned the following in the Sandbox.
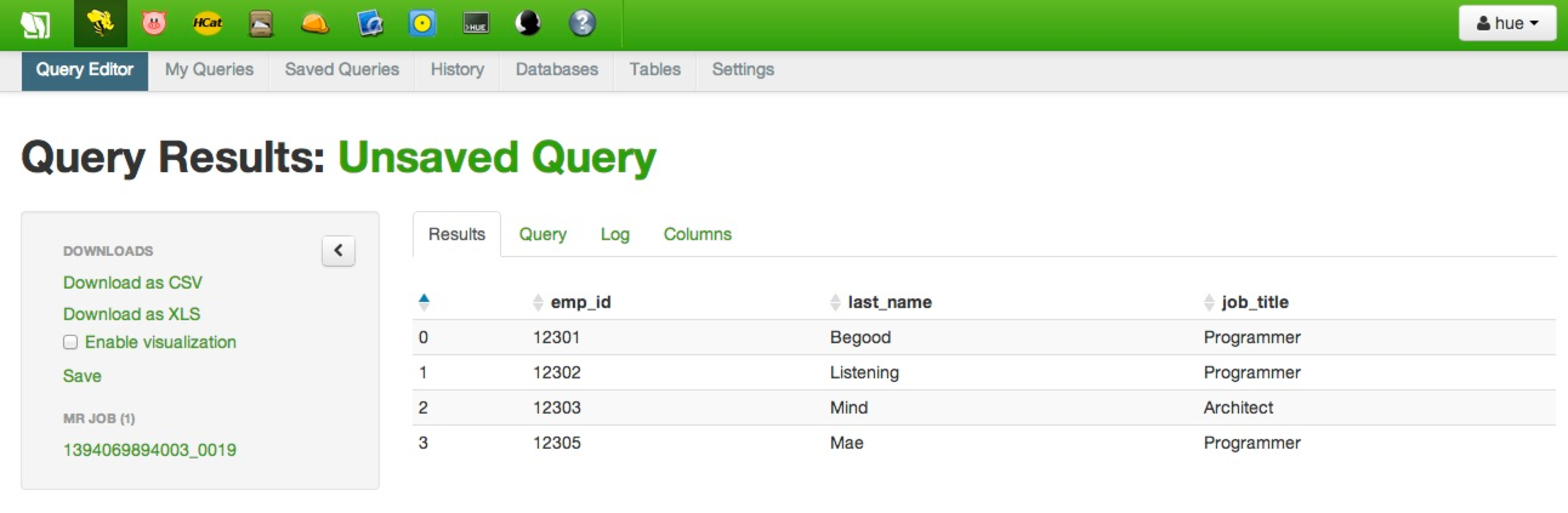
There you have it – a super simple way to get a fixed-width file into a table that you can query from hive.