installing hdp 2.2 with ambari 2.0 (moving to the azure cloud)
I've got a lot of miles running small testing clusters leveraging VirtualBox VMs based on the write up I did a while back at building a virtualized 5-node HDP 2.0 cluster (all within a mac), but as the comments section suggests, it is time to move to the cloud. HDP is continuing to grow and the 2.2 stack I've installed that way simply has more components than it did several months ago in the 2.0 version and these clusters are starting to crawl. Innovation waits for no one!
BTW, the Hortonworks Sandbox, http://hortonworks.com/products/hortonworks-sandbox, is still a great option for exploring & learning Hadoop!!
I already had an account setup on https://portal.azure.com from some earlier testing, including running the Sandbox on Azure as detailed at http://hortonworks.com/blog/hortonworks-sandbox-azure/ and deploying a pre-configured HDP cluster as described in http://hortonworks.com/blog/azure-iaas-getting-started-guide/, so I decided to use Microsoft's Azure as my cloud provider for this exercise. You'll need to create an account if you haven't done so already and are thinking about replicating my steps. I also did some dabbling around with a few of the host types identified on http://azure.microsoft.com/en-us/pricing/details/virtual-machines/#Linux and decided I'd use the A6 Standard for my cluster nodes.
Despite my staunch recommendations at a robust set of hadoop master nodes (it is hard to swing it with two machines) for strong node stereotypes, I've also decided I would start this cluster out with only three nodes total. Yes, I'm going to make them all masters AND workers. If it wasn't clear... that's NOT what I'd recommend for any "real" cluster. I am mainly thinking of the costs I'm about to incur and this will still be much, much more than I usually run in my VirtualBox VMs on my mac.
So... let's get started!

As you see above, I decided to use the OpenLogic CentOS 6.6 VM image that Azure has. I identified the hostname as hdp22-node1 and I'm betting you can guess what the other two names will be. I then let it get provisioned and requested for it to be started. From the next screenshot, you can find the domain name for this server.
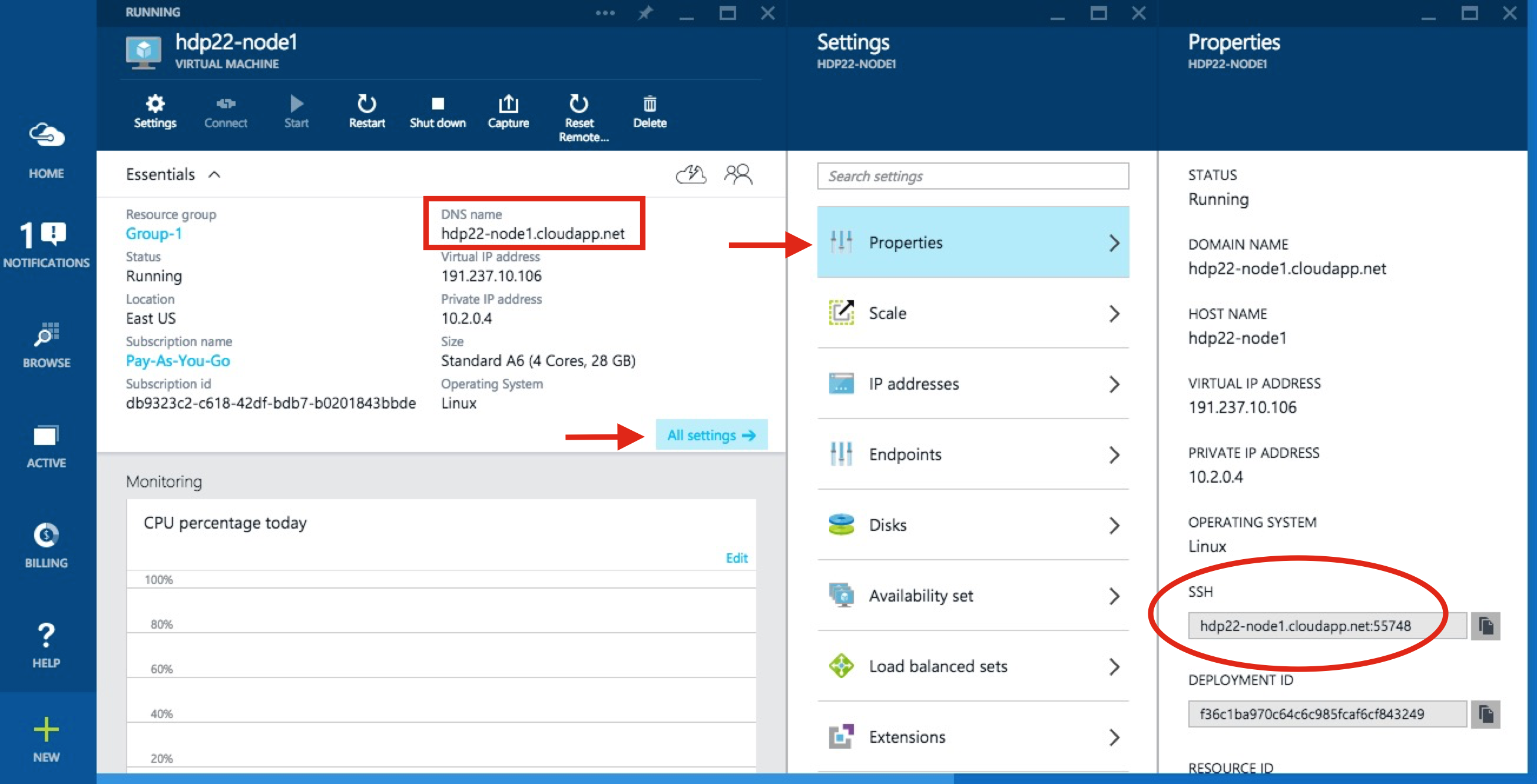
You can also find the specific port needed to make an SSH connection which I was able to connect from my mac as shown below.
HW10653:azure lmartin$ ssh -p 55748 lester@hdp22-node1.cloudapp.net
Warning: Permanently added '[hdp22-node1.cloudapp.net]:55748,[191.237.10.106]:55748' (RSA) to the list of known hosts.
lester@hdp22-node1.cloudapp.net's password:
[lester@hdp22-node1 ~]$ hostname -f
hdp22-node1.hdp22-node1.b4.internal.cloudapp.net
[lester@hdp22-node1 ~]$ sudo -s
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
[sudo] password for lester:
[root@hdp22-node1 lester]# whoami
root
[root@hdp22-node1 lester]# cd ~
[root@hdp22-node1 ~]# pwd
/root
[root@hdp22-node1 ~]#
I also echoed out the internal hostname that will be using later during the Ambari install to reference all of the hosts by as well as verified I could become root. Next up is tackling the disk configurations, so let's see what this new host has right now.
[root@hdp22-node1 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 29G 2.4G 25G 9% / tmpfs 14G 0 14G 0% /dev/shm /dev/sdb1 281G 63M 267G 1% /mnt/resource [root@hdp22-node1 ~]#
The second and third filesystems shown above are for Azure as described here, so let's just ignore them. The root file system has about 25GB free which is in line with HDP 2.2's File System Partitioning Recommendations for the base OS plus all of HDP's binaries, configuration files, and logs. The recommendations page also suggests a /grid/[0-n] naming scheme for the worker's JBOD filesystem configuration. In this dual-purpose master/worker configuration I decided to use four 1TB drives, but I'm going to deviate a bit and number them from 1-4 instead of 0-3.
I followed the Azure instructions at http://azure.microsoft.com/en-us/documentation/articles/virtual-machines-linux-how-to-attach-disk/ for a guided walk-thru of setting up these four disks per machine. The output below was done after I created all three machines and got their filesystems lined-up for an HDP installation.
HW10653:azure lmartin$ ssh -p 55748 lester@hdp22-node1.cloudapp.net lester@hdp22-node1.cloudapp.net's password: Last login: Wed May 6 23:10:53 2015 from c-98-192-80-103.hsd1.ga.comcast.net [lester@hdp22-node1 ~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 29G 2.4G 25G 9% / tmpfs 14G 0 14G 0% /dev/shm /dev/sdc1 1007G 72M 956G 1% /grid/1 /dev/sdf1 1007G 72M 956G 1% /grid/2 /dev/sdd1 1007G 72M 956G 1% /grid/3 /dev/sde1 1007G 72M 956G 1% /grid/4 /dev/sdb1 281G 63M 267G 1% /mnt/resource [lester@hdp22-node1 ~]$ ssh hdp22-node2.hdp22-node2.b2.internal.cloudapp.net The authenticity of host 'hdp22-node2.hdp22-node2.b2.internal.cloudapp.net (10.2.0.5)' can't be established. RSA key fingerprint is ed:41:8e:ad:04:48:d7:09:b2:34:2a:0a:5c:68:f5:b8. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hdp22-node2.hdp22-node2.b2.internal.cloudapp.net,10.2.0.5' (RSA) to the list of known hosts. lester@hdp22-node2.hdp22-node2.b2.internal.cloudapp.net's password: Last login: Wed May 6 23:20:27 2015 from c-98-192-80-103.hsd1.ga.comcast.net [lester@hdp22-node2 ~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 29G 2.4G 25G 9% / tmpfs 14G 0 14G 0% /dev/shm /dev/sdc1 1007G 72M 956G 1% /grid/1 /dev/sdf1 1007G 72M 956G 1% /grid/2 /dev/sde1 1007G 72M 956G 1% /grid/3 /dev/sdd1 1007G 72M 956G 1% /grid/4 /dev/sdb1 281G 63M 267G 1% /mnt/resource [lester@hdp22-node2 ~]$ ssh hdp22-node3.hdp22-node3.b2.internal.cloudapp.net The authenticity of host 'hdp22-node3.hdp22-node3.b2.internal.cloudapp.net (10.2.0.6)' can't be established. RSA key fingerprint is 67:ef:b9:9b:2a:67:ab:ff:59:ba:6d:2c:d1:85:d2:e3. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hdp22-node3.hdp22-node3.b2.internal.cloudapp.net,10.2.0.6' (RSA) to the list of known hosts. lester@hdp22-node3.hdp22-node3.b2.internal.cloudapp.net's password: Last login: Wed May 6 23:28:47 2015 from c-98-192-80-103.hsd1.ga.comcast.net [lester@hdp22-node3 ~]$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 29G 2.4G 25G 9% / tmpfs 14G 0 14G 0% /dev/shm /dev/sdc1 1007G 72M 956G 1% /grid/1 /dev/sdd1 1007G 72M 956G 1% /grid/2 /dev/sde1 1007G 72M 956G 1% /grid/3 /dev/sdf1 1007G 72M 956G 1% /grid/4 /dev/sdb1 281G 63M 267G 1% /mnt/resource [lester@hdp22-node3 ~]$
The mkfs command was the real time killer in this exercise. Now that we've got that taken care of, make sure you have a solution to run commands on multiple boxes such as describe in a lightning quick tutorial on pdsh (for when you need to run the same command on many machines). At this point, it is time to follow the Installing HDP Using Ambari 2.0.0 documentation. You can see some detailed walkthrus of these at building a virtualized 5-node HDP 2.0 cluster (all within a mac), but again, the Ambari docs are pretty solid and will get you through this. The following bullet list calls out the items I did from those instructions.
- Setup Up Password-less SSH
- Edit the Network Configuration File
- Configuring iptables
- Disable SELinux and PackageKit and check the umask Value
- Download the Ambari Repo
- Set Up the Ambari Server
- Start the Ambari Server
Now it is time to pull up the Ambari UI which should look something like my http://hdp22-node1.cloudapp.net:8080 link, but you should NOT be able to access it. This is because we need to create an Azure "endpoint" to allow this traffic thru. Back in the Azure Portal, click into your Ambari server, then All settings and Endpoints.
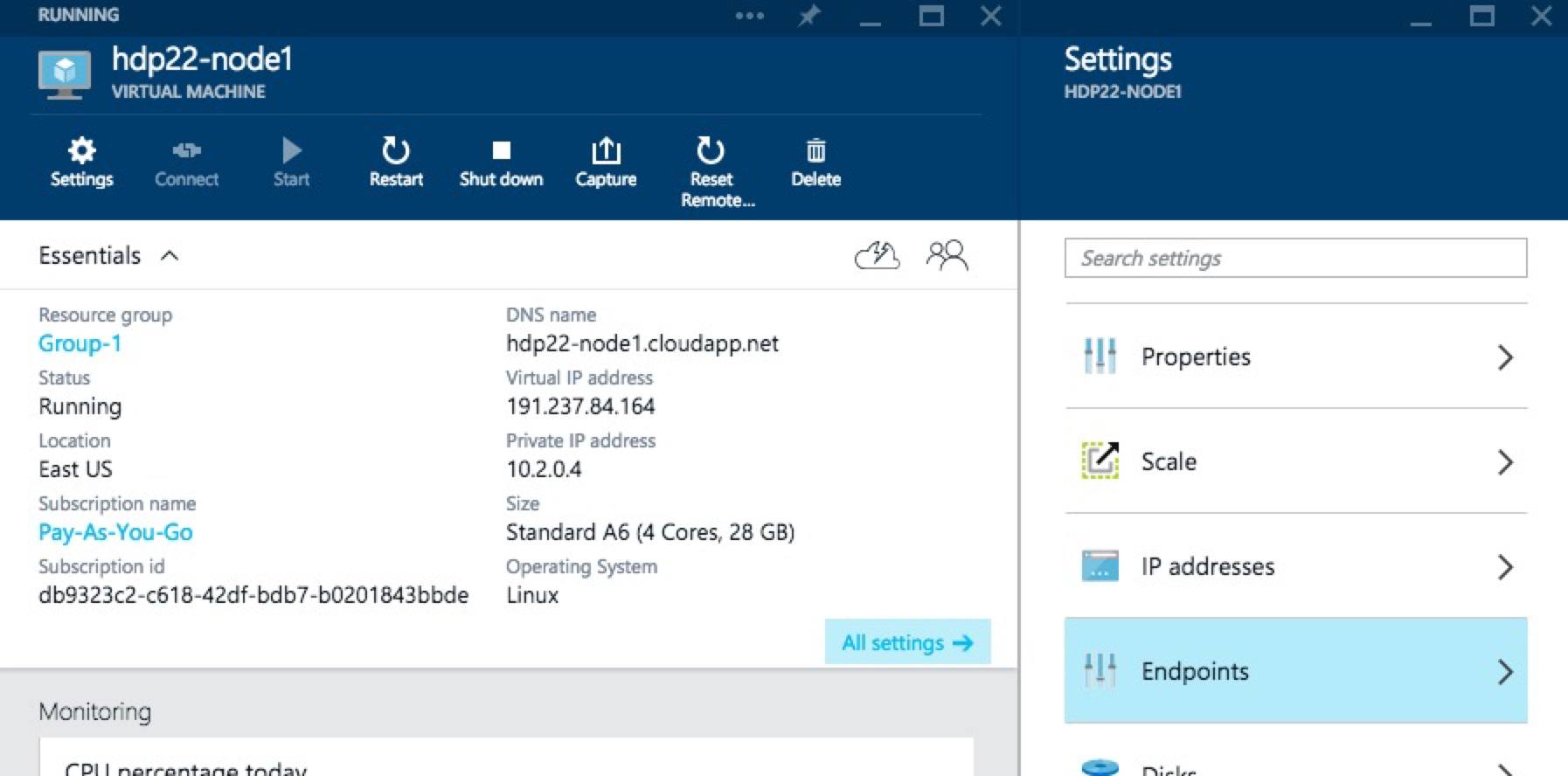
Then Add a new one as shown below and click OK to save it.
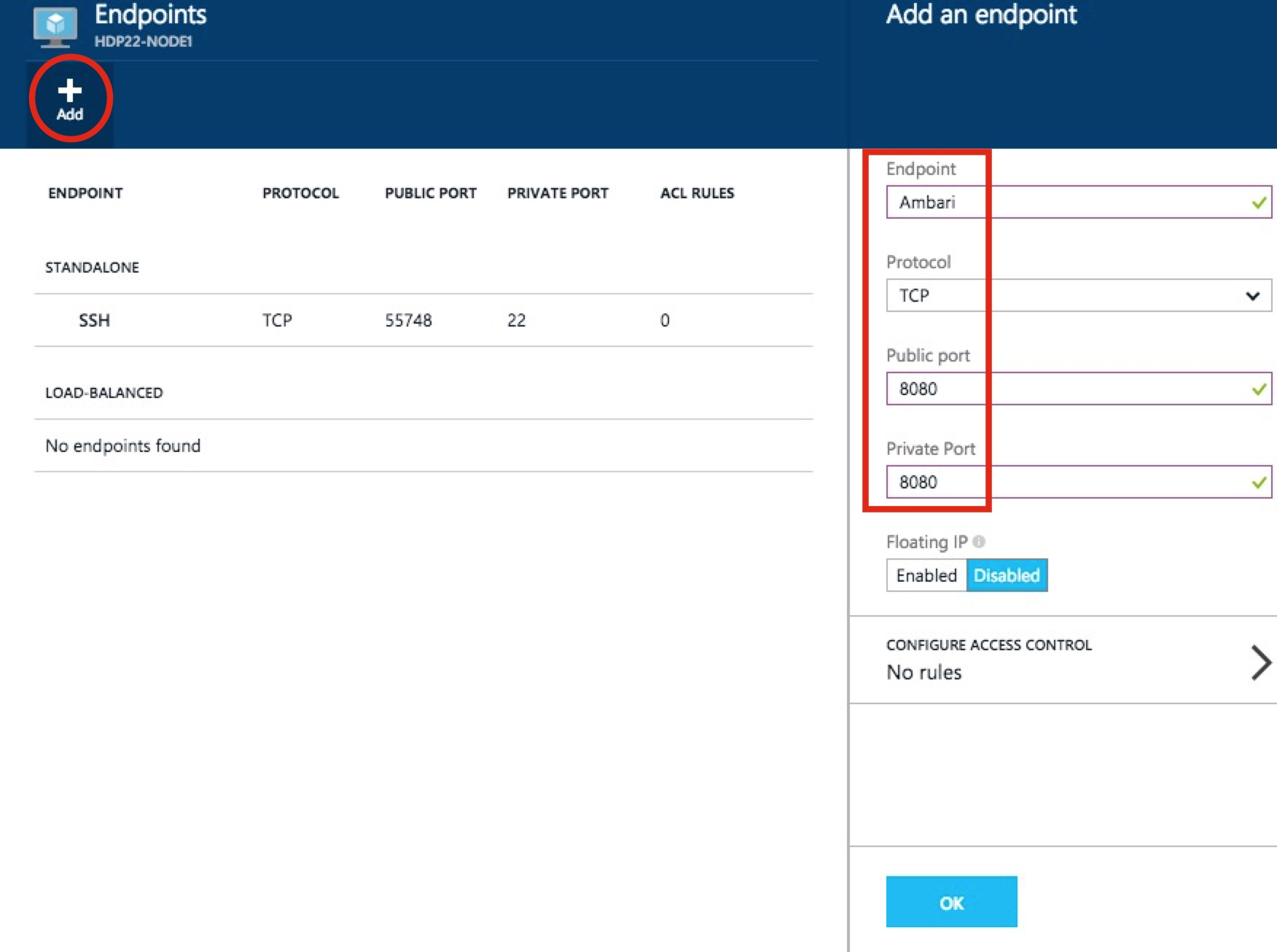
Now you should be able to get in!!
Now you can resume with the Launching the Ambari Install Wizard which should be the next step in the instructions after the bullet list items from above. Remember to use the "internal" FQDNs you got from the hostname -f output as well as the private key data from the /root/.ssh/id_rsa file you created earlier.
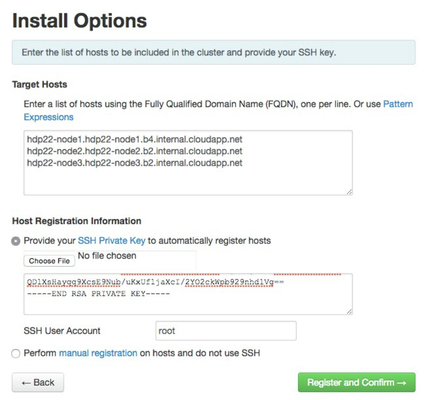
I did get hit with waning about the ntpd service not running, but I ignored it since it clearly looks like these Azure hosted VMs are in lock-step on time sync. I was also warned that Transparent Huge Pages (THP) was enabled and I ignored it because, well frankly just because this is still just a test cluster and I needed to keep moving forward in my install. ![]() On the Choose Services wizard step, I deselected HBase as it isn't in my upcoming use cases and these VMs are already going to be taxed trying to be masters and workers. I spread out the masters servers as shown below.
On the Choose Services wizard step, I deselected HBase as it isn't in my upcoming use cases and these VMs are already going to be taxed trying to be masters and workers. I spread out the masters servers as shown below.

With the (again, not recommended!) strategy of making each node a master and a worker, I simply checked all boxes on the Assign Slaves and Clients screen. As usual, there are some things that have to be addressed on the Customize Services screen. For the Hive, Oozie, and Knox tabs you are required for selecting a password for each of these components. There are some other changes that need to be made. For those properties than can (and should!) support multiple directories, Ambari tries to help out. In most cases it adds the desired /grid/[1-4] mount points, but usually also brings in the "special" Azure filesystem, too. The following table identifies the properties that need some attention prior to moving forward.
| Tab | Section | Property | Action | Notes |
|---|---|---|---|---|
| HDFS | NameNode | NameNode directories | Replace all with /hadoop/hdfs/namenode | Not ideal, but we'll probable reconfigure to HA NN later |
| NameNode Java heap size | Reduce to 2048 | 10752 was a good starter place, but Ambari was imagining this node would be primarily focused on running the NameNode, but 10GB is too big of a slice of the A6's 28GB memory | ||
| NameNode new generation size | Reduce to 512 | Keeping inline with heap size | ||
| NameNode maximum new generation size | Reduce to 512 | Same as previous | ||
| Secondary NameNode | SecondaryNameNode Checkpoint directories | Trim down to just /hadoop/hdfs/namesecondary | Again, not ideal, but it'll get us going for now | |
| DataNode | DataNode directories | Remove the /mnt/resource/hadoop/hdfs/data entry | The /grid/[1-4] based entries are aligned with our JBOD strategy | |
| DataNode volumes failure toleration | Increase to 1 | Allow one of the 4 drives on each worker to be unavailable and still serve as a DN | ||
| YARN | Node Manager | yarn.nodemanager.log-dir | Remove the /mnt/resource/hadoop/yarn/log entry | |
| yarn.nodemanager.local-dirs | Remove the /mnt/resource/hadoop/yarn/local entry | |||
| Application Timeline Server | yarn.timeline-service.leveldb-timeline-store.path | Trim down to just /hadoop/yarn/timeline | ||
| ZooKeeper | ZooKeeper Server | ZooKeeper directory | Trim down to just /hadoop/zookeeper | |
| Falcon | Falcon startup.properties | *.falcon.graph.storage.directory | Trim off leading /grid/1 path | |
| *.falcon.graph.serialize.path | Trim off leading /grid/1 path | |||
| Storm | General | storm.local.dir | Trim off leading /grid/1 path | |
| Kafka | Kafka Broker | log.dirs | Remove the /mnt/resource/kafka-logs entry |
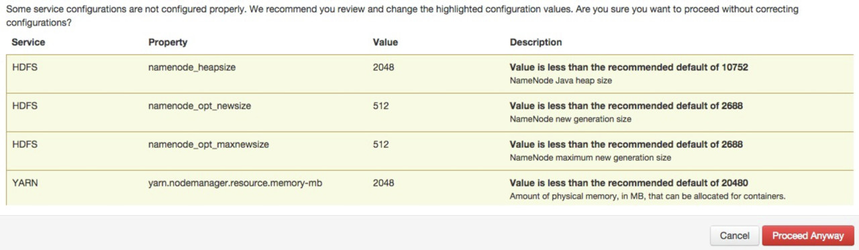
When I finally moved passed this screen, I got the following warnings (ignore the NM one as I backed that change out later) which are basically telling us to let the NN and NM processes have more memory, but we just don't have it and this should not be a problem for the kinds of limited workloads I'll be running on this cluster.
After a somewhat longer install process than i was expecting, I found out that only the DataNode that was running on the same node as the NameNode was actually functioning correctly. After some searching I realized that this is likely due to Azure's use of DHCP and I found this StackOverflow article that helped. Using Ambari (i.e Services > HDFS > Config > Custom hdfs-site > Add Property...) I was able to add the following KVP.
<property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property>
This seemed to get things going again. At least enough to play around with the cluster some more.
To kick the tires, I created a user with the simple hadoop cluster user provisioning process (simple = w/o pam or kerberos) and then did a hadoop mini smoke test (VERY mini) to know that the basic install is working correctly.
I did several complete shutdowns and restarts to include the underlying VMs themselves. The whole DHCP nature of these particular VMs (i.e. I'm too cheap for static IPs, but in hindsight it would have been smarter and saved a LOT of time) is allowing more problems to creep up. After letting 12+ hours pass I must have finally gotten totally new DHCP leases as I dug into the ambari-agent logs when Ambari signaled it could not even get a heartbeat from any of the worker nodes. I went to the ambari-agent configuration file and made the following change.
[server] hostname=REMOVE_THE_IP_AND_REPLACE_WITH_FQDN
After making that change on all three config files and issuing the ambari-agent restart command, Ambari could then communicate with the hosts and successfully started up the cluster.
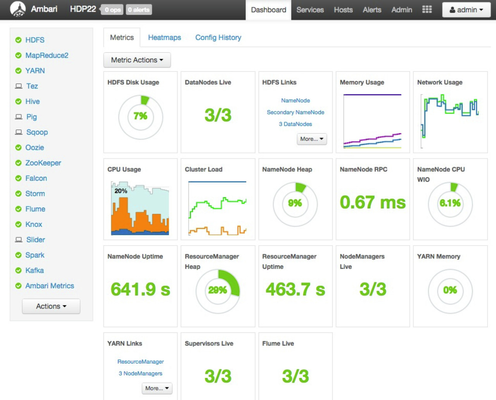
I am a bit concerned there are still some lingering IP-oriented problems and the cost is already seeming to be a bit prohibitive for me to spend too much time with the cluster operational, but I will share more problems & their resolutions as I encounter them. With this HDP cluster running on Azure, I'll wrap up another (mildly successful) Hadoop blog posting!!