![]() As a follow-up to create and share a pig udf (anyone can do it) I thought I'd post a similarly focused write-up on how you can put your custom Hive UDF jars on HDFS to let all users utilize the functions you create. As detailed in HIVE-6380, if you are already on Hive 0.13 (HDP 2.1) then notice the one-liner way to do all of this at the bottom of that last Hive wiki link. As for me, I'm using the Hortonworks Sandbox version 2.0 again, so I have to do it with a whopping two lines as you'll see below. Also, as with the Pig UDF tutorial I can't get the example to run successfully with Hue's Hive UI. So... we'll stick with the CLI for this quick blog post.
As a follow-up to create and share a pig udf (anyone can do it) I thought I'd post a similarly focused write-up on how you can put your custom Hive UDF jars on HDFS to let all users utilize the functions you create. As detailed in HIVE-6380, if you are already on Hive 0.13 (HDP 2.1) then notice the one-liner way to do all of this at the bottom of that last Hive wiki link. As for me, I'm using the Hortonworks Sandbox version 2.0 again, so I have to do it with a whopping two lines as you'll see below. Also, as with the Pig UDF tutorial I can't get the example to run successfully with Hue's Hive UI. So... we'll stick with the CLI for this quick blog post.
First up, make sure you have a Hive table that you can run a SELECT statement on. I'll be using the employees table I created in how do i load a fixed-width formatted file into hive? (with a little help from pig).
Then we'll need a UDF itself. As there are good tutorials on this already on the web I'm just going to use the "to upper" function described in http://gethue.com/hadoop-tutorial-hive-udf-in-1-minute/. I pulled down the precompiled jar instead of building it – grab it yourself; myudfs.jar. I put it in the /user/hue/shared/hive/udfs HDFS directory. If you crack that open you'll find the source for the actual UDF.
package org.hue.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class MyUpper extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toUpperCase() + "-gg");
}
}
Yes... he's adding an extra -gg at the end, but that will make it that much easier to notice all is working fine. Now we just need a Hive query to declare this function and then use it.
ADD JAR hdfs:///user/hue/shared/hive/udfs/myudfs.jar; CREATE TEMPORARY FUNCTION my_upper AS 'org.hue.udf.MyUpper'; SELECT first_name, my_upper(last_name) FROM employees;
Just like with the example in create and share a pig udf (anyone can do it), Hue does not seem to like this and errors out very quickly. Again, bonus points for running this one down. So, we fall back on our trusty CLI to execute the script.
[hue@sandbox ~]$ hive -f SelectWithUDFonHDFS.hql ... LOTS of lines removed ... OK 1234567890123456789 1234567890123456789-gg FIRST-NAME LASTNAME-gg Johnny BEGOOD-gg Ainta LISTENING-gg Neva MIND-gg Joseph BLOW-gg Sallie MAE-gg Bilbo BAGGINS-gg Nuther ONE-gg Yeta NOTHERONE-gg Evenmore DUMBNAMES-gg Last SILLYNAME-gg Time taken: 20.264 seconds, Fetched: 12 row(s)
As with the Pig UDF, it worked; this time with Hive! You did it!! Everything was CAPITALIZED (and got an extra trailing bit of nonsense at no extra charge)!!! Congratulations!!!!

The Apache Pig project's User Defined Functions gives a pretty good overview of how to create a UDF. In fact, I stole my simple UDF from there. For Pig UDF's the obligitory "Hello World" program is actually a "Convert to Upper Case" function. For this effort, I'm using the Hortonworks Sandbox (version 2.0). Once you have that setup operational, follow along and we'll get your first UDF created and placed on HDFS where others can easily share it.
Follow the Sandbox's instructions to log into the VM (root's password is hadoop), but then switch user to hue (bonus points for why this is really a bad idea) before opening up a new file called UPPER.java.
hw10653:~ lmartin$ ssh root@127.0.0.1 -p 2222 root@127.0.0.1's password: Last login: Fri Mar 28 21:34:47 2014 from 10.0.2.2 [root@sandbox ~]# su hue [hue@sandbox root]$ cd ~ [hue@sandbox ~]$ mkdir exampleudf [hue@sandbox ~]$ cd exampleudf [hue@sandbox exampleudf]$ vi UPPER.java
Paste in the following code to the vi editor. If you "forgot" how, just type i to pop into insert mode and then paste the stuff from below (and... if you needed that little hint, then bang the ESC key a couple of times and then type :wq and press ENTER to write the file and quit vi – google for a good vi cheat sheet if needed).
package exampleudf;
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class UPPER extends EvalFunc<String>
{
public String exec(Tuple input) throws IOException {
if(input == null || input.size() == 0 || input.get(0) == null)
return null;
try {
String str = (String)input.get(0);
return str.toUpperCase();
} catch(Exception e) {
throw new IOException("Caught exception processing input row ", e);
}
}
}
As you are starting to see, the goal is to create a SIMPLE User-Defined Function. This will give you a strawman that you can build your own slick new function on top of. That, or pay some decent Java Hadoop programmer to do it for you – heck, I'm not allergic to a little moonlighting. ![]()
Then just compile the class and jar it up (your jdk and pig version numbers might vary slightly). If you have trouble compiling/jaring it, or don't even want to try, then just download exampleudf.jar directly and load it into the directory described further down in the post.
[hue@sandbox exampleudf]$ /usr/jdk64/jdk1.6.0_31/bin/javac -cp /usr/lib/pig/pig-0.12.0.2.0.6.0-76.jar UPPER.java [hue@sandbox exampleudf]$ cd .. [hue@sandbox ~]$ /usr/jdk64/jdk1.6.0_31/bin/jar -cf exampleudf.jar exampleudf [hue@sandbox ~]$ ls -l *.jar -rw-rw-r-- 1 hue hue 1534 Mar 29 00:54 exampleudf.jar
Now that we've got it created let's share it. The best way to make it accessible to everyone is to put the jar file on HDFS itself. Since we are using the Sandbox, we could just use Hue, but everything is always more fun at the command line.
[hue@sandbox ~]$ hadoop fs -mkdir shared [hue@sandbox ~]$ hadoop fs -mkdir shared/pig [hue@sandbox ~]$ hadoop fs -mkdir shared/pig/udfs [hue@sandbox ~]$ ls -l *.jar -rw-rw-r-- 1 hue hue 1534 Mar 29 00:54 exampleudf.jar [hue@sandbox ~]$ hadoop fs -put exampleudf.jar shared/pig/udfs/exampleudf.jar [hue@sandbox ~]$ hadoop fs -ls /user/hue/shared/pig/udfs Found 1 items -rw-r--r-- 3 hue hue 1534 2014-03-29 00:59 /user/hue/shared/pig/udfs/exampleudf.jar
If all went well you should be able to see that file via Hue's File Browser.
For this compiled UDF library to be accessible for everyone, the jar file needs to have its HDFS permissions set to allow read rights for all users.
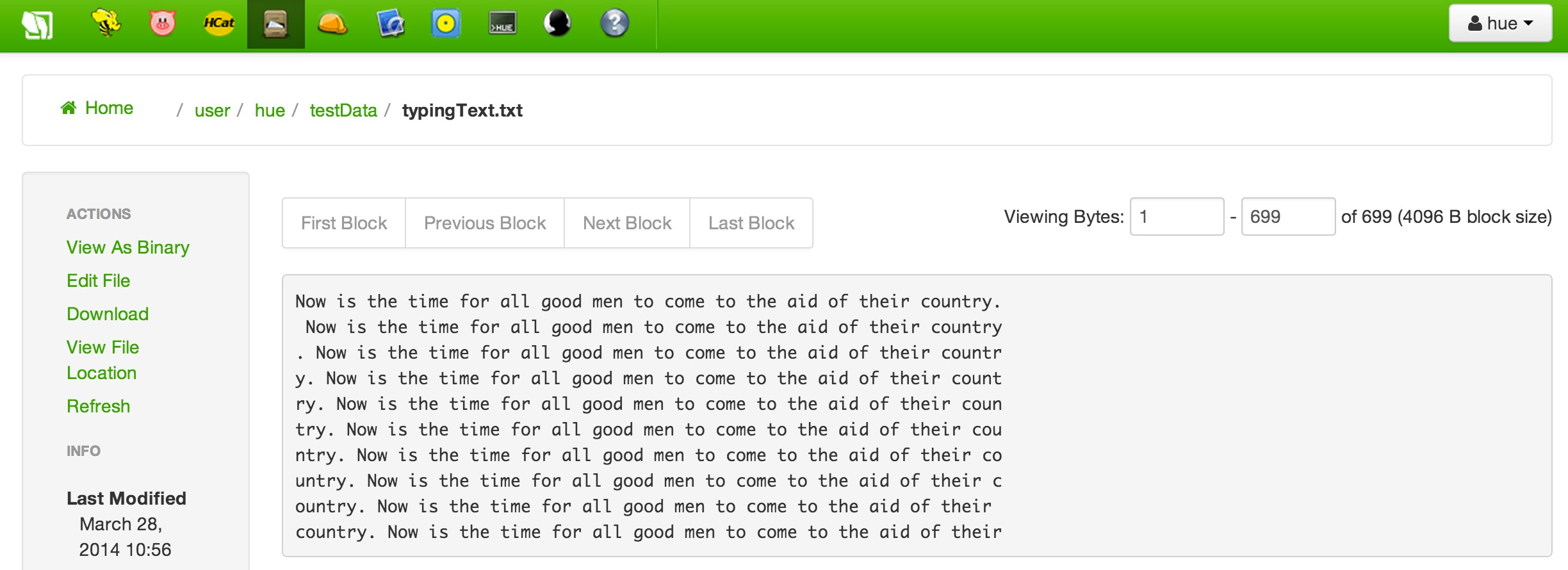
Now, create a file (example: typingText.txt) with some random text such and get it into HDFS as shown below.
Next up; write a simple Pig script that will register the UDF jar file from HDFS and then use to turn all the words into upper-case.
REGISTER 'hdfs:///user/hue/shared/pig/udfs/exampleudf.jar'; DEFINE SIMPLEUPPER exampleudf.UPPER(); typing_line = LOAD '/user/hue/testData/typingText.txt' AS (row:chararray); upper_typing_line = FOREACH typing_line GENERATE SIMPLEUPPER(row); DUMP upper_typing_line;
The logical thing would be to use the Pig UI component of Hue to run this super simple function, but I simply cannot figure out why it complains with the following error each time.
2014-03-29 01:15:19,712 [main] ERROR org.apache.pig.tools.grunt.Grunt - ERROR 2999: Unexpected internal error. Pathname /tmp/udfs/'hdfs:/user/hue/shared/pig/udfs/exampleudf.jar' from hdfs://sandbox.hortonworks.com:8020/tmp/udfs/'hdfs:/user/hue/shared/pig/udfs/exampleudf.jar' is not a valid DFS filename.
I simply could NOT work past this error and decided to do what everyone should do when something doesn't work (more bonus points if you can get it to work in Hue's Pig UI) – I made the problem simpler. I went back to my trusty old friend, the command-line interface (CLI).
[hue@sandbox ~]$ pig test-UPPER.pig 2014-03-29 01:20:40,579 [main] INFO org.apache.pig.Main - Apache Pig version 0.12.0.2.0.6.0-76 (rexported) compiled Oct 17 2013, 20:44:07 2014-03-29 01:20:40,580 [main] INFO org.apache.pig.Main - Logging error messages to: /usr/lib/hue/pig_1396081240577.log ... LOTS of lines removed ... 2014-03-29 01:21:12,501 [main] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2014-03-29 01:21:12,502 [main] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1 (NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COUNTRY.) ( NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COUNTRY) (. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COUNTR) (Y. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COUNT) (RY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COUN) (TRY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR COU) (NTRY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR CO) (UNTRY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR C) (OUNTRY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR ) (COUNTRY. NOW IS THE TIME FOR ALL GOOD MEN TO COME TO THE AID OF THEIR)
It worked! You did it!! Everything has been CAPITALIZED!!! Congratulations!!!!
This write-up was for an issue, and resolution, on a HDP 1.3.2 installation. Default properties (and behavior!) can surely change in future releases, but the general message should be relevant regardless which version of Hadoop you are using.
One of my clients came to me with a concern about Oozie apparently running their Hive script much slower than when they kicked if off via the CLI with a hive -f SCRIPT_FILE.hql command. After a little bit of digging it seems that when run by itself there was a large number of reducers, but when Oozie ran it there was only one. That's a good clue to how to fix it.
So, first question is why does Hive not have any trouble with using multiple reducers? The answer is in the mapred.reduce.tasks configuration property of Hive. It defaults to -1 which has the following explanation (taken from Hive 0.11's HiveConf.java file).
// The number of reduce tasks per job. Hadoop sets this value to 1 by default
// By setting this property to -1, Hive will automatically determine the correct
// number of reducers.
HADOOPNUMREDUCERS("mapred.reduce.tasks", -1),
This value (if explicitly set to this default or another value) ultimately shows up in the hive-site.xml file and, again, is the reason the CLI invocation of the script runs wide.
When Oozie runs a Hive action, it seems that it decides to use the overarching MapReduce settings which by default is set to 1 as seen in Hadoop 1.1.2's default settings and then gets percolated out into the mapred-site.xml configuration file (well, if it is explicitly set to htis default or another value).
So, the answer is probably coming to you. Why not set an override in the Oozie job to let Hive "automatically determine the correct number of reducers" or even some specific value? No reason at all not do that. How to do that? Well, fortunately that's pretty darn easy.
You just need to add the property to Oozie's (3.3.2 for HDP 1.3.2) Hive Action Extension as visualized in the center of the example below.
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<action name="myfirsthivejob">
<hive xmlns="uri:oozie:hive-action:0.2">
<job-traker>foo:8021</job-tracker>
<name-node>bar:8020</name-node>
<prepare>
<delete path="${jobOutput}"/>
</prepare>
<configuration>
<property>
<name>mapred.reduce.tasks</name>
<value>-1</value>
</property>
</configuration>
<script>myscript.q</script>
<param>InputDir=/home/tucu/input-data</param>
<param>OutputDir=${jobOutput}</param>
</hive>
<ok to="myotherjob"/>
<error to="errorcleanup"/>
</action>
...
</workflow-app>
This should get you back to the same behavior as running the Hive script from the CLI.
UPDATE: Feb 5, 2015
See the comments section which identifies a better way to do this using FixedWidthLoader.
I was talking with a client earlier this week that is using the Hortonworks Sandbox to jumpstart his Hadoop learning (hey, that's exactly why we put it out there).
![]() Thanks to all the Sandbox tutorials out there he already knew how to take a delimited file, get it into HDFS, use HCatalog to build a table, and then run Hive queries against it. What he didn't know how to do was to load up a good old-fashioned fixed-width formatted file into a table. My first hunch was to use a simple Pig script to convert it into a delimited file and I told him I'd pull together a simple set of instructions to help him with his Sandbox self-training. Robert, here ya go!!
Thanks to all the Sandbox tutorials out there he already knew how to take a delimited file, get it into HDFS, use HCatalog to build a table, and then run Hive queries against it. What he didn't know how to do was to load up a good old-fashioned fixed-width formatted file into a table. My first hunch was to use a simple Pig script to convert it into a delimited file and I told him I'd pull together a simple set of instructions to help him with his Sandbox self-training. Robert, here ya go!!
Create & Upload a Test File
To try this all out we first need a little test file. Create a file called emps-fixed.txt on your workstation with the following contents (yes... the first two lines are part of the exploration, but they don't break anything either).
12345678901234567890123456789012345678901234567890123456789012345678901234567890 EMP-ID FIRST-NAME LASTNAME JOB-TITLE MGR-EMP-ID 12301 Johnny Begood Programmer 12306 12302 Ainta Listening Programmer 12306 12303 Neva Mind Architect 12306 12304 Joseph Blow Tester 12308 12305 Sallie Mae Programmer 12306 12306 Bilbo Baggins Development Manager 12307 12307 Nuther One Director 11111 12308 Yeta Notherone Testing Manager 12307 12309 Evenmore Dumbnames Senior Architect 12307 12310 Last Sillyname Senior Tester 12308
Then upload the file into HDFS and just land it in your home directory on the Sandbox.
I'm taking some creative liberty and assuming that you've worked through (or at least understand the concepts of) some/most/all of the Sandbox tutorials. For example, check out Tutorial 1 to see how to upload this file. If at any point in this blog posting you are unfamiliar with how to do an activity, check back with the tutorials for help. If you can't find which one can help you, let me know in the comments section and I'll reply with more info.
At this point, you should have a /user/hue/emps-fixed.txt file sitting in HDFS.
Build a Converter Script
Now we just need to build a simple converter script. There are plenty of good resources out there on Pig including the tutorials; I'm even trying to build up a Pig Cheat Sheet. For the one you'll see below, I basically stripped down the info found at https://bluewatersql.wordpress.com/2013/04/17/shakin-bacon-using-pig-to-process-data/ (remember, a lazy programmer is a good programmer & imitation is the sincerest form of flattery) which is worth checking out.
Using the Sandbox lets create a Pig script called convert-emp which will start out with some plumbing. Yes, that base "library" is called the piggy bank – I love the name, too!!
REGISTER piggybank.jar; define SUBSTRING org.apache.pig.piggybank.evaluation.string.SUBSTRING(); fixed_length_input = load '/user/hue/emps-fixed.txt' as (row:chararray);
Then build a structure using the SUBSTRING function to pluck the right values out of each line. Lastly, just write this new structure into a file on HDFS.
employees = foreach fixed_length_input generate
(int)TRIM(SUBSTRING(row, 0, 9)) AS emp_id,
TRIM(SUBSTRING(row, 10, 29)) AS first_name,
TRIM(SUBSTRING(row, 30, 49)) AS last_name,
TRIM(SUBSTRING(row, 50, 69)) AS job_title,
(int)TRIM(SUBSTRING(row, 70, 79)) AS mgr_emp_id;
store employees into '/user/hue/emps-delimited';
Verify the Output File
Now you can navigate into /user/hue/emps-delimited on HDFS and you'll see the familiar (or not so familiar?) "part" file via the Sandbox's File Browser which shows the following tab-delimited content.
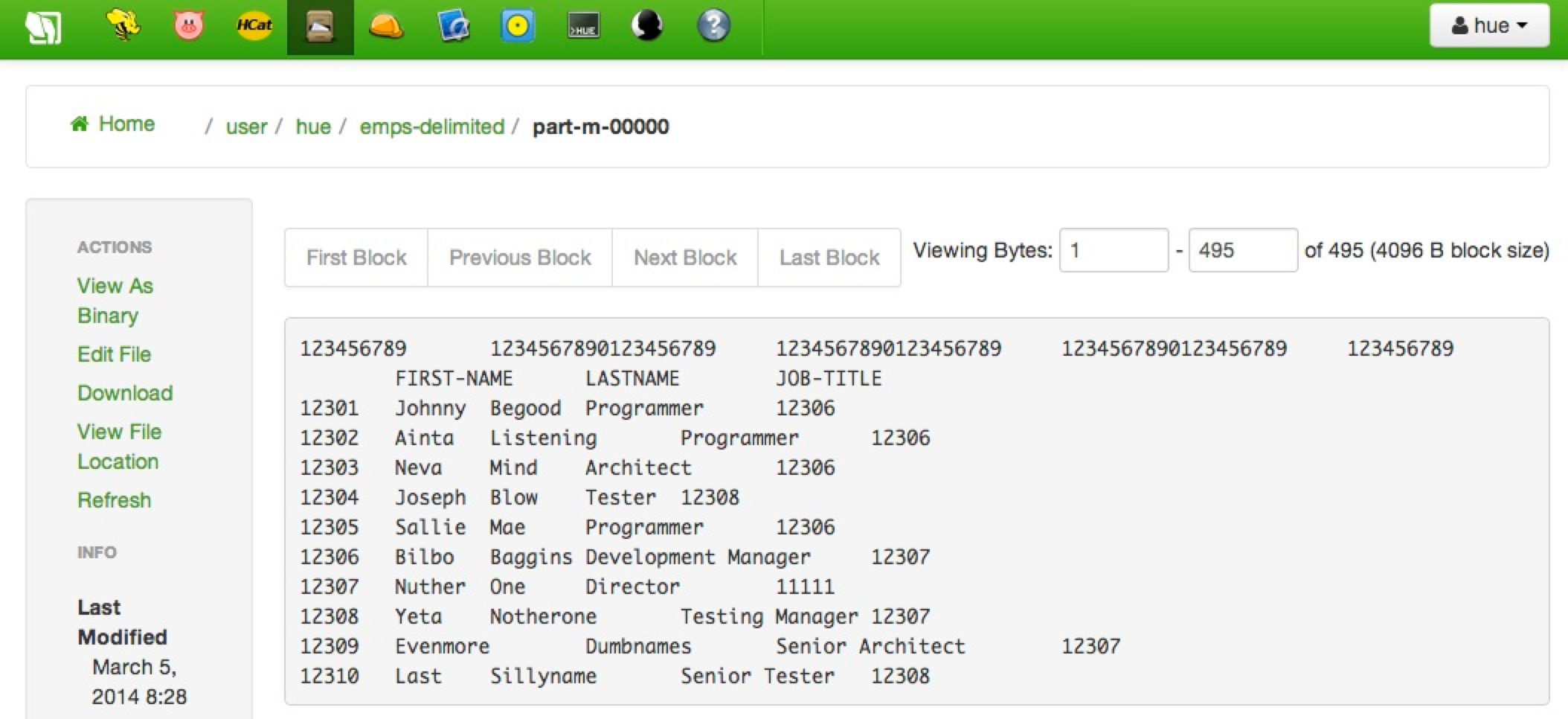
You're welcome to rerun the exercise without the first two rows, but again, they won't cause any real harm due to the forgiving nature of Pig who tries its best to do what you tell it to do. For the "real world", you'd probably want to write some validation logic to make sure things like the value "EMP-ID" (from the source file) fails miserable when trying to be cast to an integer.
Load a Table and Run a Query
Now you need to create a table based on this delimited file (hint, see Tutorial 1 again for one way to do that) and then run a simple query to verify all works. I ran the following HiveQL.
select emp_id, last_name, job_title from employees where mgr_emp_id = 12306;
It returned the following in the Sandbox.
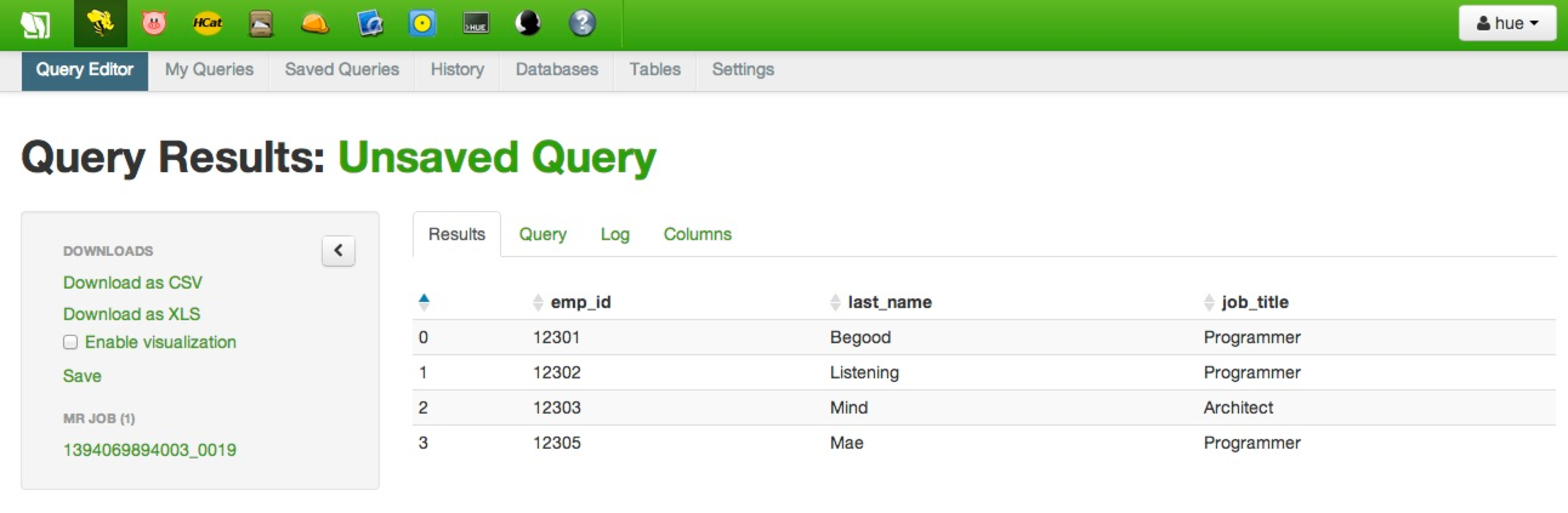
There you have it – a super simple way to get a fixed-width file into a table that you can query from hive.
What a great (and exhausting!) week at the Hortonworks Palo Alto office. I learned a lot; and more importantly I met some great people. I'm so excited to be on this journey and to be at Hortonworks!! A handful of us that had a bit of time before out flights where scheduled to leave (that's me; I'm on the red-eye tonight and I'm blogging this from the SFO airport) decided to head over to the Computer History Museum. It is across the street from the Googleplex and amazingly enough we ended up two cars behind one of Google's cool self-driving cars.

Kind of frustrating that a computer drives a better car than me, but hey... this blog post is about the computers anyway. Speaking of computers, the museum has an AWESOME Babbage Machine.


They cranked it a bit until the operator decided it had a slightly different feel to it that he didn't like. Hey, he's a volunteer – he won't even lose any money if they fire him. Seriously, it was pretty cool in action as you can see on their web page.
The museum had some very, very early computing devices. You know, the stuff that filled a room and had something like 16K of memory. These things could even process thousands of instructions per section. ![]() A lot of those early computing days centered on the military. They even had a German Enigma Machine.
A lot of those early computing days centered on the military. They even had a German Enigma Machine.

I got it! It we would have just switched the letter Z with the letter Y in all those transmissions we would have broken their code!! ![]()
The first real device I saw that hit home was a trusty old IBM S/360. I started my career on the mainframe and the "big iron" still holds a special place in my heart; I'm just glad I missed the card machines days!

The S/360 project leader also brought us an important book way back then whose message is just as relevant today. How did it go? Something about nine women not being able to have a baby in one month?

Speaking of Big Blue, a bit later on the tour was a machine that I was lucky enough to work on during my co-op days at IBM; the mighty RISC 6000. AIX was my first real experience with Unix and I fell in love with it. The (then) giant 24" CRT monitors were pretty cool, too.

The very end of the tour focused on more recent advancements such as cell phones, the commercialized Internet, and even iPods, but I truly enjoyed the computers of my youth. Sure, there were some Apples (II's, Lisas, and of course Macs), but would could ever forget the Trash 80's, my beloved TRS-80 line.

The wildly popular $99 Sinclair...

And, of course, Commodore's VIC-20 and C64.

There was also a fun set of exhibits focused on early video gaming. They had my personal favorite system; the Atari 2600. Notice this one is a 4-switcher with "real" simulated wood-grain.

This makes me want to dig out my old 2600 console and plug in classics like Yars Revenge and Pitfall and play like I was 14 again. Of course, my son is 14 now and he was NOT impressed the last time I pulled out this game system to show him. The video games today are truly awesome, but nothing can replace my memories of growing up on this machine in the 1980's.
So, if you find yourself in the Silicon Valley just south of San Francisco and have a couple of hours to burn, I do recommend the Computer History Museum. Well... that is if you're a true geek!