![]() This post represents the completion of the trilogy started in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series) and use pig to calculate salary statistics for georgia educators (second of a three-part series). As the name suggests, we're going to try to solve a simple question (specifically the one listed at Simple Open Georgia Use Case) with Apache Hive and compare/contrast a bit on this approach vs. MapReduce or Pig.
This post represents the completion of the trilogy started in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series) and use pig to calculate salary statistics for georgia educators (second of a three-part series). As the name suggests, we're going to try to solve a simple question (specifically the one listed at Simple Open Georgia Use Case) with Apache Hive and compare/contrast a bit on this approach vs. MapReduce or Pig.
As before, be sure to check out the content at Open Georgia Analysis & Preparing Open Georgia Test Data for the context of this discussion and make sure you have a working copy of the Hortonworks Sandbox if you want to test any of the information presented for yourself.
The first thing we need to do is build a Hive table on top of the data we previously loaded at /user/hue/opengeorgia/salaryTravelReport.csv in HDFS. There are many different options that can be explored when creating a Hive table, but we're looking for simplicity so we will emulate the instructions from the "Create tables for the Data Using HCatalog" section of the Sandbox's Tutorial #4.
I went ahead and created a new database called opengeorgia via Hue's HCat UI, as well. I then created a table named salary using the CSV file above as the "Input File" and used the options visualized below (pardon the "chop job").
When reproducing the actions from this blog out on HDP 1.3 for Windows that I set up during installing hdp on windows (and then running something on it) I realized that the screenshot below omitted the orgType column (string datatype). You can see that in https://github.com/lestermartin/hadoop-exploration/blob/master/src/main/hive/opengeorgia/CreateSalaryTable.hql.
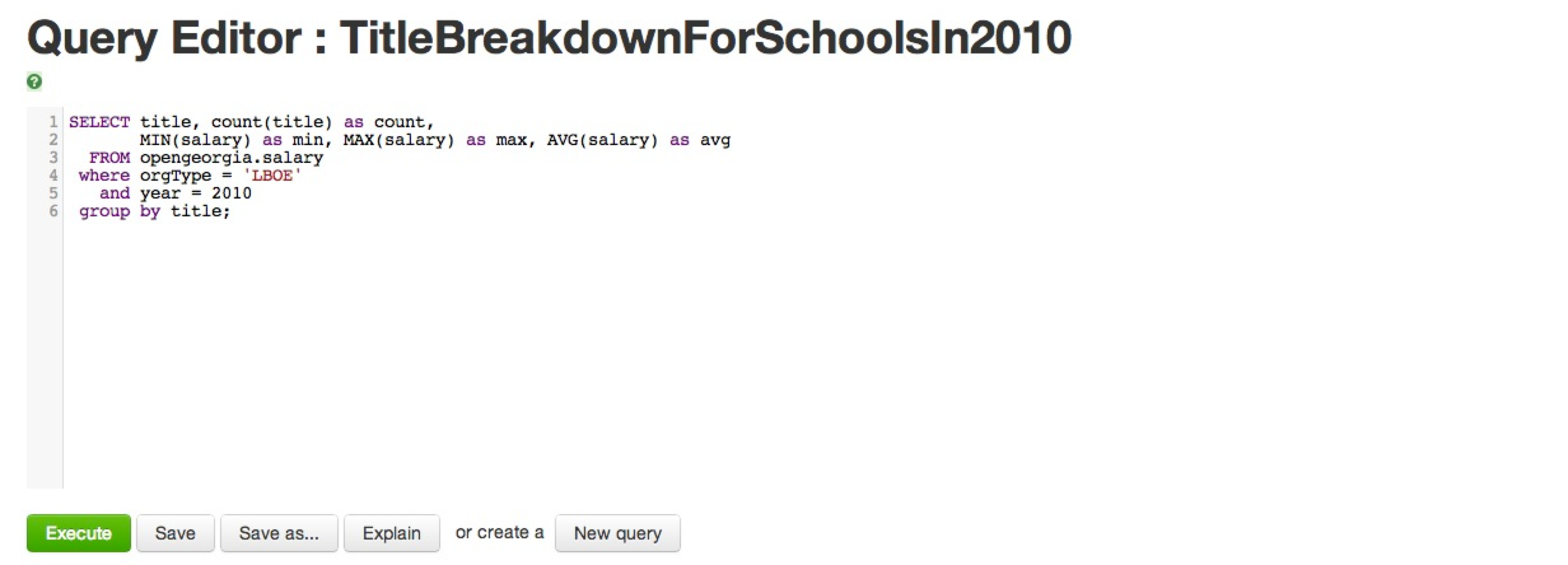
Now, do a quick double-check by running a "select count(*) from opengeorgia.salary;" query from Hue's Query Editor within the Beeswax (Hive) UI. You should be told there are 76,943 rows in the newly created table if you built (or just downloaded) the file described in Format & Sample Data for Open Georgia. To actually answer the question raised in Simple Open Georgia Use Case you really won't have to do much more than that as seen below. This query is also saved as TitleBreakdownForSchoolsIn2010.hql in the GitHub > lestermartin > hadoop-exploration project.
The results in Hue should look like the following.
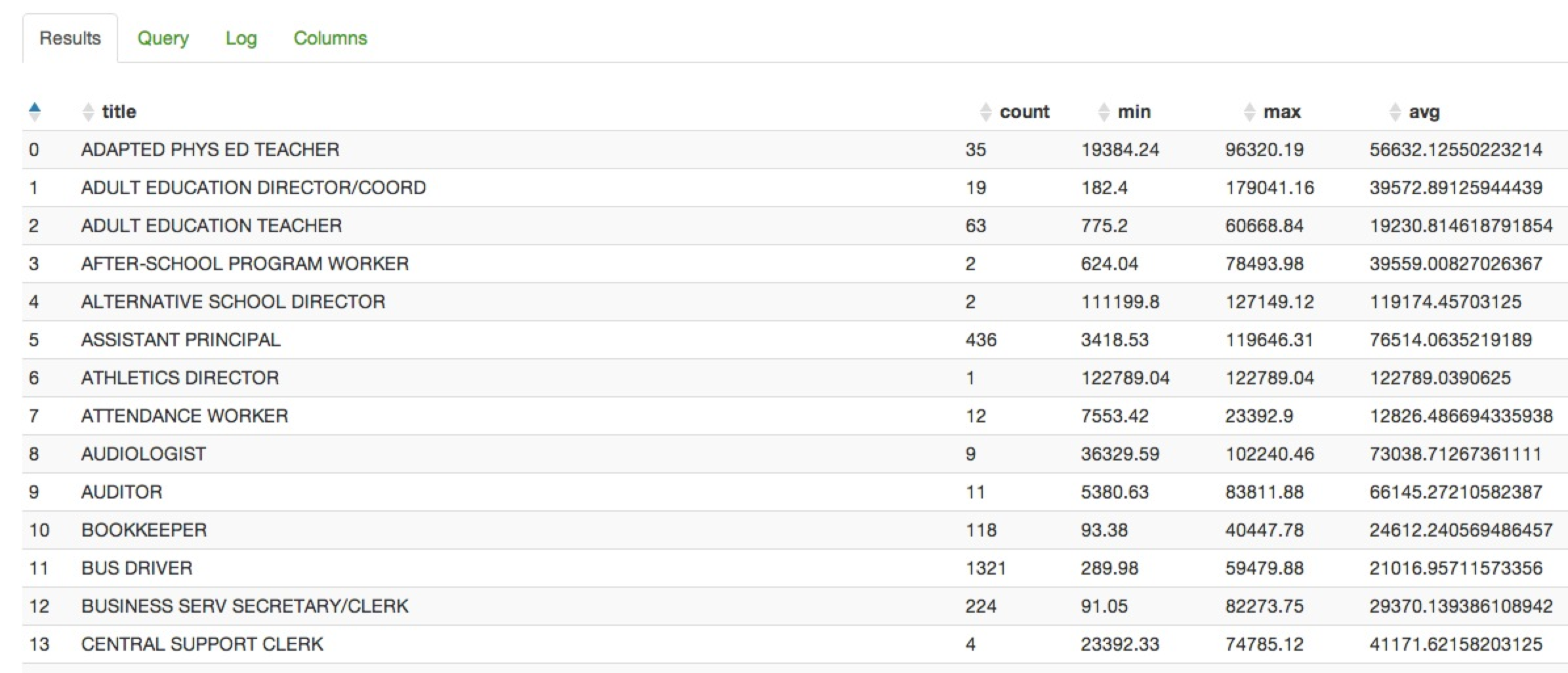
Walking these results we see the same answers as we did with MapReduce and Pig. Our spot-checks were to double-check that the 9 Audiologists's salaries (see screenshot above) averaged out to be $73,038.71 and later in the results that the highest paid 3rd Grade Teacher from this dataset made $102,263.29. I also verified that there were 181 rows reported (note: Hue's query results begin with 0, not 1).
Obviously, we expected all the computations to deliver the same results. The real purpose of these three blog postings was to show that there are different tools in the Hadoop ecosystem and that each have their own sweet spot. For this well-formed data and simple/typical reporting use case it is easy to see that Hive makes much more sense than MapReduce or even Pig. As I said before, the answer is most often "it depends" and this is clearly not a "Hive is best for everything" statement, so please take it in the spirit it was offered.
I hope you got something out of this post and its predecessors; use mapreduce to calculate salary statistics for georgia educators (first of a three-part series) and use pig to calculate salary statistics for georgia educators (second of a three-part series). Comments & feedback are always appreciated – even if they are critical; well... constructively critical.
 In this the second installment of a three-part series, I am going to show how to use Apache Pig to solve the same Simple Open Georgia Use Case that we did in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series), but this time I'll do it with a lot less code. Pig is a great "data pipelining" technology and our simple need to parse, filter, calculate statistics, sort, and then save the Format & Sample Data for Open Georgia is right up its alley.
In this the second installment of a three-part series, I am going to show how to use Apache Pig to solve the same Simple Open Georgia Use Case that we did in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series), but this time I'll do it with a lot less code. Pig is a great "data pipelining" technology and our simple need to parse, filter, calculate statistics, sort, and then save the Format & Sample Data for Open Georgia is right up its alley.
Be sure to check out the write-up at Open Georgia Analysis to ensure you have the right context before going on in this posting. This will drive you to Preparing Open Georgia Test Data to help you generate (or just download) a sample dataset to perform analysis on. You will also want to make sure you have a working copy of the Hortonworks Sandbox to do your testing with.
The Pig code is also in the GitHub > lestermartin > hadoop-exploration project and the script itself can be found at TitleStatisticsForSchoolsIn2010.pig. To replace the five classes described in the lestermartin.hadoop.exploration.opengeorgia package we used just 10 lines of Pig code as discussed below.
The first two lines are just some housekeeping activities. I often have trouble with Hue's Pig UI and the REGISTER command so as the comments section of create and share a pig udf (anyone can do it) shows, I usually solve this by putting my UDF jars on HDFS itself (including the "piggybank"). You'll see the use of the REPLACE function in a bit.
-- load up the base UDF (piggybank) and get a handle on the REPLACE function register /user/hue/shared/pig/udfs/piggybank.jar; define REPLACE org.apache.pig.piggybank.evaluation.string.REPLACE();
Then we simply load the CSV file that we have on HDFS into a structure we defined in-stream. The CSVExcelStorage class is a lifesaver as you can see from SalaryReportBuilder we weren't able to simple tokenize the input based on finding a comma.
-- load the salary file and declare its structure inputFile = LOAD '/user/hue/opengeorgia/salaryTravelReport.csv' using org.apache.pig.piggybank.storage.CSVExcelStorage() as (name:chararray, title:chararray, salary:chararray, travel:chararray, orgType:chararray, org:chararray, year:int);
Since there is all kinds of mess in the Salary and Travel Expenses fields, I initially declared them as simple strings. The next line does some light cleanup on these two values so I could cast them as floats. I took out the dollar signs back in my Preparing Open Georgia Test Data notes, but if they were present it would be easy enough to strip them out just like I'm doing with the commas.
-- loop thru the input data to clean up the number fields a bit cleanedUpNumbers = foreach inputFile GENERATE name as name, title as title, (float)REPLACE(salary, ',','') as salary, -- take out the commas and cast to a float (float)REPLACE(travel, ',','') as travel, -- take out the commas and cast to a float orgType as orgType, org as org, year as year;
The next three pipelining statements just toss out those records that don't meet the criteria of the Simple Open Georgia Use Case and the lump up all the data by the job title – very synonymous to what we explicitly did in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series) with our TitleMapper class.
-- trim down to just Local Boards of Education onlySchoolBoards = filter cleanedUpNumbers by orgType == 'LBOE'; -- further trim it down to just be for the year in question onlySchoolBoardsFor2010 = filter onlySchoolBoards by year == 2010; -- bucket them up by the job title byTitle = GROUP onlySchoolBoardsFor2010 BY title;
Now we get down to the brass tacks of actually calculating the statistics we've been after. The built-in functions make that easy enough.
-- loop through the titles and for each one... salaryBreakdown = FOREACH byTitle GENERATE group as title, -- we grouped on this above COUNT(onlySchoolBoardsFor2010), -- how many people with this title MIN(onlySchoolBoardsFor2010.salary), -- determine the min MAX(onlySchoolBoardsFor2010.salary), -- determine the max AVG(onlySchoolBoardsFor2010.salary); -- determine the avg
Truthfully, this final "do something" bit of code looks a lot like snippet below from SalaryStatisticsReducer that we built in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series).
for(FloatWritable value : values) {
float salary = value.get();
numberOfPeopleWithThisJobTitle++;
totalSalaryAmount = totalSalaryAmount + salary;
if(salary < minSalary)
minSalary = salary;
if(salary > maxSalary)
maxSalary = salary;
}
Then we quickly make sure the output will be sorted the way we want it.
-- guarantee the order on the way out sortedSalaryBreakdown = ORDER salaryBreakdown by title;
Lastly, line 10 writes the output file into HDFS. There's a commented out alternative that simply displays the contents to the console (be it Hue in our case or the CLI if you're running the script that way).
-- dump results to the UI --dump sortedSalaryBreakdown; -- save results back to HDFS STORE sortedSalaryBreakdown into '/user/hue/opengeorgia/pigoutput';
The following bit of confirmation log information was easy enough to get to from Hue's Pig UI.
2014-04-30 04:35:01,442 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete 2014-04-30 04:35:01,532 [main] INFO org.apache.pig.tools.pigstats.SimplePigStats - Script Statistics: HadoopVersion PigVersion UserId StartedAt FinishedAt Features 2.2.0.2.0.6.0-76 0.12.0.2.0.6.0-76 yarn 2014-04-30 04:33:29 2014-04-30 04:35:01 GROUP_BY,ORDER_BY,FILTER Success! Job Stats (time in seconds): JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs job_1398691536449_0085 1 1 7 7 7 7 4 4 4 4 byTitle,cleanedUpNumbers,inputFile,onlySchoolBoards,salaryBreakdown GROUP_BY,COMBINER job_1398691536449_0086 1 1 4 4 4 4 3 3 3 3 sortedSalaryBreakdown SAMPLER job_1398691536449_0087 1 1 4 4 4 4 3 3 3 3 sortedSalaryBreakdown ORDER_BY /user/hue/opengeorgia/pigoutput, Input(s): Successfully read 76943 records (7613119 bytes) from: "/user/hue/opengeorgia/salaryTravelReport.csv" Output(s): Successfully stored 181 records (11278 bytes) in: "/user/hue/opengeorgia/pigoutput" Counters: Total records written : 181 Total bytes written : 11278 Spillable Memory Manager spill count : 0 Total bags proactively spilled: 0 Total records proactively spilled: 0
It confirms that same in/out counts that we saw in use mapreduce to calculate salary statistics for georgia educators (first of a three-part series); 76,943 input records and 181 output records. Here's a snapshot of what the output file looks like from Hue's File Browser.
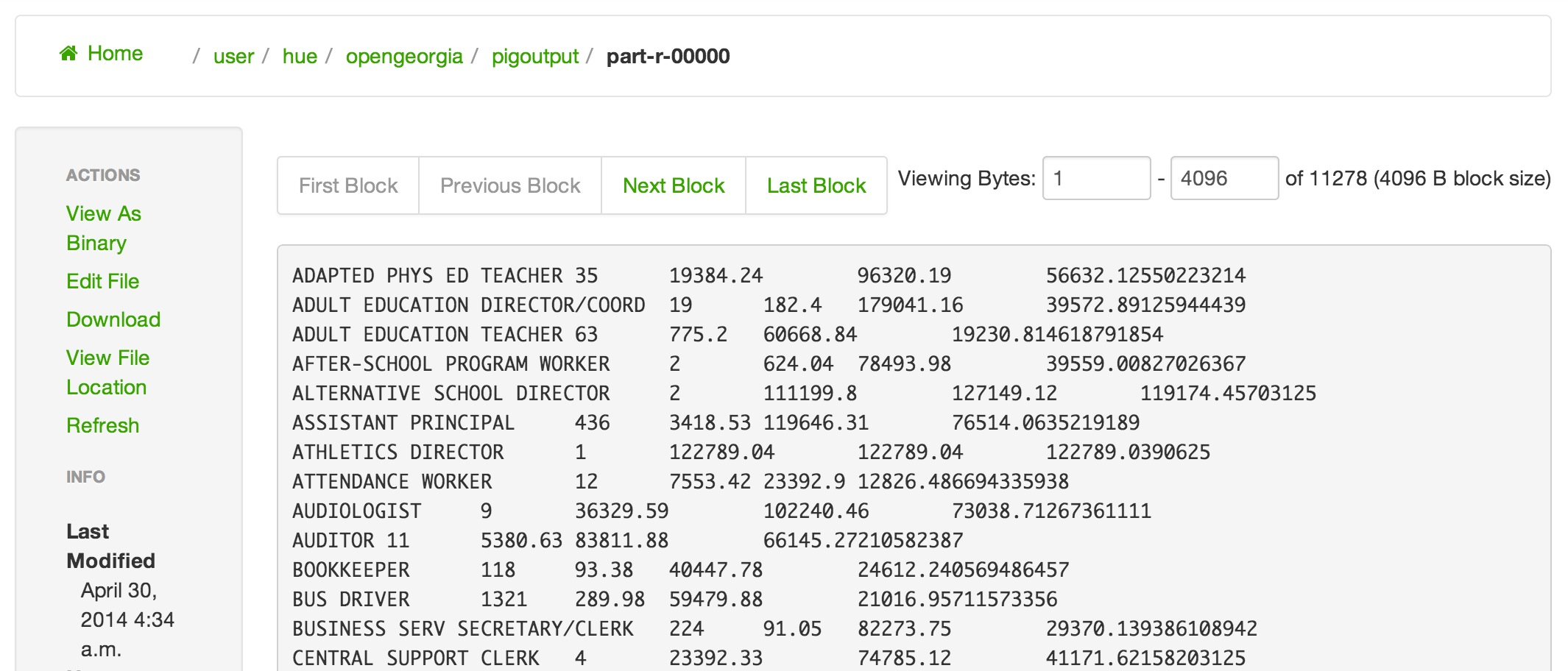
As before, we were able to answer the Simple Open Georgia Use Case question. Just as important, a close look at the output between this solution and the MapReduce one showed the spot-check values of the average salary for the 9 Audiologists is consistent at $73,038.71 (see above screenshot) as well as both correctly indicating that the highest paid 3rd Grade Teacher from this dataset is making $102,263.29.
The default answer for consulting is "it depends" is the same answer for questions about Hadoop. When you put those together then the resounding answer for Hadoop consulting is "IT DEPENDS", but I do feel for this particular Simple Open Georgia Use Case using the Format & Sample Data for Open Georgia that Pig is a better solution than Java MapReduce. That surely won't be the case always, but the simplicity of this Pig script surely makes it the winner for this situation when only looking at these two options. We'll just have to wait and see if the final installment of this series declares Hive an even better alternative than Pig to this problem.
This is the first of a three-part series on showing alternative Hadoop & Big Data tools being utilized for Open Georgia Analysis. The data we are working against looks like the following which is an include of the Format & Sample Data for Open Georgia wiki page.
The following describes the format of the dataset used for Open Georgia Analysis and was created by the process described in Preparing Open Georgia Test Data.
| NAME (String) | TITLE (String) | SALARY (float) | TRAVEL (float) | ORG TYPE (String) | ORG (String) | YEAR (int) |
|---|---|---|---|---|---|---|
| ABBOTT,DEEDEE W | GRADES 9-12 TEACHER | 52,122.10 | 0.00 | LBOE | ATLANTA INDEPENDENT SCHOOL SYSTEM | 2010 |
| ALLEN,ANNETTE D | SPEECH-LANGUAGE PATHOLOGIST | 92,937.28 | 260.42 | LBOE | ATLANTA INDEPENDENT SCHOOL SYSTEM | 2010 |
| BAHR,SHERREEN T | GRADE 5 TEACHER | 52,752.71 | 0.00 | LBOE | COBB COUNTY SCHOOL DISTRICT | 2010 |
| BAILEY,ANTOINETTE R | SCHOOL SECRETARY/CLERK | 19,905.90 | 0.00 | LBOE | COBB COUNTY SCHOOL DISTRICT | 2010 |
| BAILEY,ASHLEY N | EARLY INTERVENTION PRIMARY TEACHER | 43,992.82 | 120.00 | LBOE | COBB COUNTY SCHOOL DISTRICT | 2010 |
| CALVERT,RONALD MARTIN | STATE PATROL (SP) | 51,370.40 | 62.00 | SABAC | PUBLIC SAFETY, DEPARTMENT OF | 2010 |
| CAMERON,MICHAEL D | PUBLIC SAFETY TRN (AL) | 34,748.60 | 259.35 | SABAC | PUBLIC SAFETY, DEPARTMENT OF | 2010 |
| DAAS,TARWYN TARA | GRADES 9-12 TEACHER | 41,614.50 | 0.00 | LBOE | FULTON COUNTY BOARD OF EDUCATION | 2011 |
| DABBS,SANDRA L | GRADES 9-12 TEACHER | 79,801.59 | 41.00 | LBOE | FULTON COUNTY BOARD OF EDUCATION | 2011 |
| E'LOM,SOPHIA L | IS PERSONNEL - GENERAL ADMIN | 75,509.00 | 613.73 | LBOE | FULTON COUNTY BOARD OF EDUCATION | 2012 |
| EADDY,FENNER R | SUBSTITUTE | 13,469.00 | 0.00 | LBOE | FULTON COUNTY BOARD OF EDUCATION | 2012 |
| EADY,ARNETTA A | ASSISTANT PRINCIPAL | 71,879.00 | 319.60 | LBOE | FULTON COUNTY BOARD OF EDUCATION | 2012 |

In this first installment, let's jump right in where Hadoop began; MapReduce. After you visit Preparing Open Georgia Test Data and get some test data loaded into HDFS, then you'll want to clone my GitHub repo as referenced in GitHub > lestermartin > hadoop-exploration. Once you have the code up in your favorite IDE (mine is IntelliJ on my MBPro) then you'll want to hone in on the lestermartin.hadoop.exploration.opengeorgia package (details on the major MapReduce stereotypes in that last link). You can then build the jar file with Maven; or just grab hadoop-exploration-0.0.1-SNAPSHOT.jar.
As with all three editions of this blog posting series, let's use the Hortonworks Sandbox to run everything. Make sure the hue user has a folder to put your jar in and then put it there.
HW10653:target lmartin$ ssh root@127.0.0.1 -p 2222 root@127.0.0.1's password: Last login: Tue Apr 29 16:48:05 2014 from 10.0.2.2 [root@sandbox ~]# su hue [hue@sandbox root]$ cd ~ [hue@sandbox ~]$ mkdir jars [hue@sandbox ~]$ exit exit [root@sandbox ~]# exit logout Connection to 127.0.0.1 closed. HW10653:target lmartin$ ls classes maven-archiver generated-sources surefire-reports generated-test-sources test-classes hadoop-exploration-0.0.1-SNAPSHOT.jar HW10653:target lmartin$ scp -P 2222 hadoop-exploration-0.0.1-SNAPSHOT.jar root@127.0.0.1:/usr/lib/hue/jars root@127.0.0.1's password: hadoop-exploration-0.0.1-SNAPSHOT.jar 100% 22KB 22.2KB/s 00:00 HW10653:target lmartin$ ssh root@127.0.0.1 -p 2222 root@127.0.0.1's password: Last login: Tue Apr 29 17:48:35 2014 from 10.0.2.2 [root@sandbox ~]# su hue [hue@sandbox root]$ cd ~/jars [hue@sandbox jars]$ ls -l total 24 -rw-r--r-- 1 root root 22678 Apr 29 18:49 hadoop-exploration-0.0.1-SNAPSHOT.jar
Now go ahead and kick it off.
[hue@sandbox jars]$ hdfs dfs -ls /user/hue/opengeorgia
Found 1 items
-rwxr-xr-x 3 hue hue 7612715 2014-04-29 16:53 /user/hue/opengeorgia/salaryTravelReport.csv
[hue@sandbox jars]$ hadoop jar hadoop-exploration-0.0.1-SNAPSHOT.jar lestermartin.hadoop.exploration.opengeorgia.GenerateStatistics opengeorgia/salaryTravelReport.csv opengeorgia/mroutput
... MANY LINES REMOVED ...
14/04/29 19:29:42 INFO input.FileInputFormat: Total input paths to process : 1
14/04/29 19:29:42 INFO mapreduce.JobSubmitter: number of splits:1
... MANY LINES REMOVED ...
14/04/29 19:29:43 INFO mapreduce.Job: Running job: job_1398691536449_0080
14/04/29 19:29:50 INFO mapreduce.Job: Job job_1398691536449_0080 running in uber mode : false
14/04/29 19:29:50 INFO mapreduce.Job: map 0% reduce 0%
14/04/29 19:29:58 INFO mapreduce.Job: map 100% reduce 0%
14/04/29 19:30:05 INFO mapreduce.Job: map 100% reduce 100%
14/04/29 19:30:05 INFO mapreduce.Job: Job job_1398691536449_0080 completed successfully
14/04/29 19:30:05 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=1279390
FILE: Number of bytes written=2726197
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=7612865
HDFS: Number of bytes written=13583
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=48256
Total time spent by all reduces in occupied slots (ms)=34216
Map-Reduce Framework
Map input records=76943
Map output records=44986
Map output bytes=1189412
Map output materialized bytes=1279390
Input split bytes=144
Combine input records=0
Combine output records=0
Reduce input groups=181
Reduce shuffle bytes=1279390
Reduce input records=44986
Reduce output records=181
Spilled Records=89972
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=146
CPU time spent (ms)=5440
Physical memory (bytes) snapshot=598822912
Virtual memory (bytes) snapshot=2392014848
Total committed heap usage (bytes)=507117568
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=7612721
File Output Format Counters
Bytes Written=13583
Here's a few records from the output (not annotating the "... MANY LINES REMOVED ..." as seen above).
[hue@sandbox jars]$ hdfs dfs -cat opengeorgia/mroutput/part-r-00000
ASSISTANT PRINCIPAL {436,3418.530029296875,119646.3125,76514.0635219189}
AUDIOLOGIST {9,36329.58984375,102240.4609375,73038.71267361111}
BUS DRIVER {1321,289.9800109863281,59479.87890625,21016.95711573356}
CROSSING GUARD {100,188.1699981689453,77890.5703125,4792.818007659912}
CUSTODIAL PERSONNEL {1393,358.0199890136719,83233.4765625,27299.229113730096}
DEPUTY/ASSOC/ASSISTANT SUPT {36,15089.6298828125,208606.71875,121005.71796332466}
ELEMENTARY COUNSELOR {265,1472.8499755859375,96220.078125,58518.51150455115}
ESOL TEACHER {450,1595.3599853515625,92835.65625,51652.298943684895}
GRADE 1 TEACHER {1041,1912.280029296875,103549.28125,49438.147760777836}
GRADE 10 TEACHER {59,3861.159912109375,94732.7421875,55489.47224659031}
GRADE 11 TEACHER {27,5537.2998046875,101728.1875,58273.76153790509}
GRADE 12 TEACHER {13,40919.26171875,92376.703125,66923.12620192308}
GRADE 2 TEACHER {1010,1843.0999755859375,95968.078125,50479.97351545579}
GRADE 3 TEACHER {1036,730.75,102263.2890625,50409.13624861433}
GRADE 4 TEACHER {873,2955.43994140625,96430.078125,52342.17116019652}
GRADE 5 TEACHER {872,1400.0,104698.0,52721.27942734465}
GRADE 6 TEACHER {239,1665.0799560546875,85595.921875,48597.56130636686}
GRADE 7 TEACHER {257,1615.260009765625,90778.078125,50304.22050220772}
GRADE 8 TEACHER {240,1746.1600341796875,85965.3828125,51121.745357767744}
GRADE 9 TEACHER {35,4128.5,90588.578125,55027.259151785714}
GRADES 6-8 TEACHER {1607,-909.8400268554688,91402.0390625,49418.24870481651}
GRADES 9-12 TEACHER {3171,200.0,119430.15625,51375.531383229296}
GRADES K-5 TEACHER {165,150.0,87925.921875,44650.884348366475}
GRADUATION SPECIALIST {63,6351.25,91945.0625,58873.631510416664}
HIGH SCHOOL COUNSELOR {225,1100.0,111393.84375,63814.18197102864}
KINDERGARTEN TEACHER {1054,1615.4100341796875,103798.0,52818.983106001506}
LIBRARIAN/MEDIA SPECIALIST {342,3208.25,97282.1875,58324.767315423975}
MIDDLE SCHOOL COUNSELOR {131,3362.93994140625,99340.078125,61327.238445252864}
MILITARY SCIENCE TEACHER {98,2328.9599609375,100116.0,62636.252752810105}
PRINCIPAL {318,2202.22998046875,159299.515625,102604.1484375}
SUBSTITUTE TEACHER {3816,-1006.5,77007.859375,8846.330627846432}
SUPERINTENDENT {3,216697.15625,411545.8125,299117.1979166667}
TEACHER SUPPORT SPECIALIST {204,2409.64990234375,96133.21875,62175.75722608379}
TECHNICAL INSTITUTE PRESIDENT {1,96884.2421875,96884.2421875,96884.2421875}
Again, many lines were removed as I just wanted an illustrative example. Being married to a Georgia educator myself, I probably am looking at these numbers and making more observations than most. For example, do we really have a Kindergarten Teacher making over $100K/year? Really?? Heck, even the highest paid Military Science Teacher is pulling in six-figures (he probably wasn't doing that on active duty!!). I also feel for the poor Substitute Teacher that was in the hole over $1000. I can say with certainty that the average pay for Principals of $102K/year surely isn't enough as that's a job with a TON of responsibilities.
Nonetheless, the goal was see if we could answer the Simple Open Georgia Use Case question which we did. The next installments will be doing the same thing, but with Pig and then Hive. Let's make sure we check to see that the average salary for the 9 Audiologists is $73,038.71 and the highest paid 3rd Grade Teacher is $102,263.29 when we perform this analysis again.
Every time I go to find a simple matrix of the two major open-source Hadoop distributions' component version list I simply can't find one. So... I created my own!!
The good news is that this blog posting is simply including the Hadoop Distribution Components & Versions wiki page so whenever it gets updated, this gets updated.
MORE CURRENT THAN BELOW; Gartner August 2020 Hadoop Distro Tracker
Tracking page for the various OPEN-SOURCE components (and their versions) for Hadoop distributions. Desire is to maintain top maintenance releases for the most recent, and one prior, major releases. Please check page history for prior versions as well as older distribution vendors.
| CDP | HDP | |||||||
|---|---|---|---|---|---|---|---|---|
| 7.0.3 | 7.1.0 | 2.6.5 | 3.1.5 | 5.16.2 | 6.3.2 | |||
| Apache Hadoop | 3.1.1 | 3.1.1 | 2.7.3 | 3.1.1 | 2.6.0 | 3.0.0 | ||
| Apache Tez | 0.9.1 | 0.9.1 | 0.7.0 | 0.9.1 | ||||
| Apache Pig | 0.16.0 | 0.16.0 | 0.12.0 | 0.17.0 | ||||
| Apache Hive | 3.1.2 | 3.1.3 | 1.2.1 & 2.1.0 | 3.1.0 | 1.1.0 | 2.1.1 | ||
| Apache Druid | 0.10.1 | 0.12.1 | ||||||
| Apache HBase | 2.2.2 | 2.2.3 | 1.1.2 | 2.1.6 | 1.2.0 | 2.1.4 | ||
| Apache Phoenix | 5.0.0 | 5.0.0 | 4.7.0 | 5.0.0 | ||||
| Apache Accumulo | 1.7.0 | 1.7.0 | ||||||
| Apache Impala | 3.2.0 | 3.3.0 | 2.12.0 | 3.2.0 | ||||
| Apache Storm | 1.1.0 | 1.2.1 | ||||||
| Apache Spark | 2.4.0 | 2.4.4 | 1.6.3 & 2.3.0 | 2.3.2 | 1.6.0 | 2.4.0 | ||
| Apache Zeppelin | 0.8.2 | 0.7.3 | 0.8.0 | |||||
| Apache Kafka | 2.3.0 | 2.3.0 | 1.0.0 | 2.0.0 | 2.2.1 | |||
| Apache Solr | 7.4.0 | 7.4.0 | 7.4.0 | 7.4.0 | 4.10.3 | 7.4.0 | ||
| Apache Sqoop | 1.4.7 | 1.4.7 | 1.4.6 | 1.4.7 | 1.4.6 | 1.4.7 | ||
| Apache Flume | 1.9.0 | 1.5.2 | rm'd | 1.6.0 | 1.9.0 | |||
| Apache Oozie | 5.1.0 | 5.1.0 | 4.2.0 | 4.3.1 | 4.1.0 | 5.1.0 | ||
| Apache ZooKeeper | 3.5.5 | 3.5.5 | 3.4.6 | 3.4.6 | 3.4.5 | 3.4.5 | ||
| Apache Atlas | 2.0.0 | ???? | 0.8.0 | 2.0.0 | ||||
| Apache Knox | 1.3.0 | 0.12.0 | 1.0.0 | |||||
| Apache Ranger | 2.0.0 | 2.0.0 | 0.7.0 | 1.2.0 | ||||
| Hue | 4.5.0 | 4.5.0 | 2.6.1 | rm'd | 3.9.0 | 4.3.0 | ||
Here is the combined distro "asparagus chart" in shiny Cloudera orange!


My alter-ego's (Jazzy Earl) Twitter feed was a bit prolific a while back.
He (me!) offered up a few more last week, too.
I hope they at least tickled your funny bones.
I needed to manually install Hue on my little cluster I previousy documented in Build a Virtualized 5-Node Hadoop 2.0 Cluster so I thought I'd document it as I went just in case it worked (and if there were any tweaks from the documentation). The Hortonworks Doc site URL for the instructions I used are at http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.0.9.0/bk_installing_manually_book/content/rpm-chap-hue.html.
One of the first things you get asked to do is to make sure Python 2.6 is installed. I ran into the following issue below that suggested I couldn't get this rolling.
[root@m1 ~]# yum install python26 Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: mirror.dattobackup.com * extras: centos.someimage.com * updates: mirror.beyondhosting.net Setting up Install Process No package python26 available. Error: Nothing to do
I'm pretty sure Ambari already laid this down so a quick double-check on the installed version was done on all my 5 nodes to verify I'm in good shape.
[root@m1 ~]# which python /usr/bin/python [root@m1 ~]# python -V Python 2.6.6
When you get to the Configure HDP page you'll be reminded that if you are using Ambari (like me) to NOT edit the conf files directly. I used vi to check the existing files in /etc/hadoop/conf to see what needed to be done. The single property for hdfs-site.xml was already in place as described. For core-site.xml, the properties starting with hadoop.proxyuser.hcat where already present as shown below.
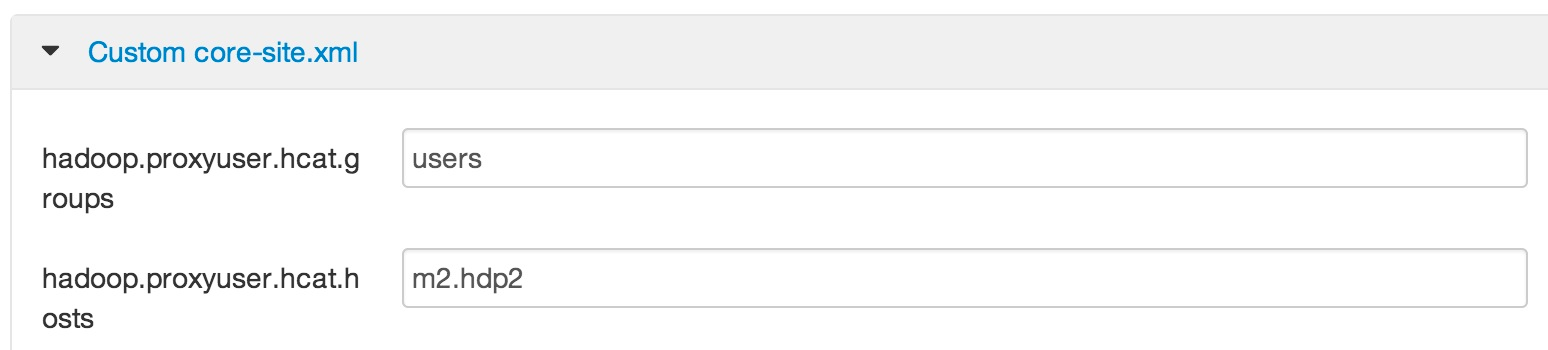
The next screenshot shows I changed them as described in the documentation. The properties starting with hadoop.proxyuser.hue where not present (no surprise!) so I added them as described (and shown below).
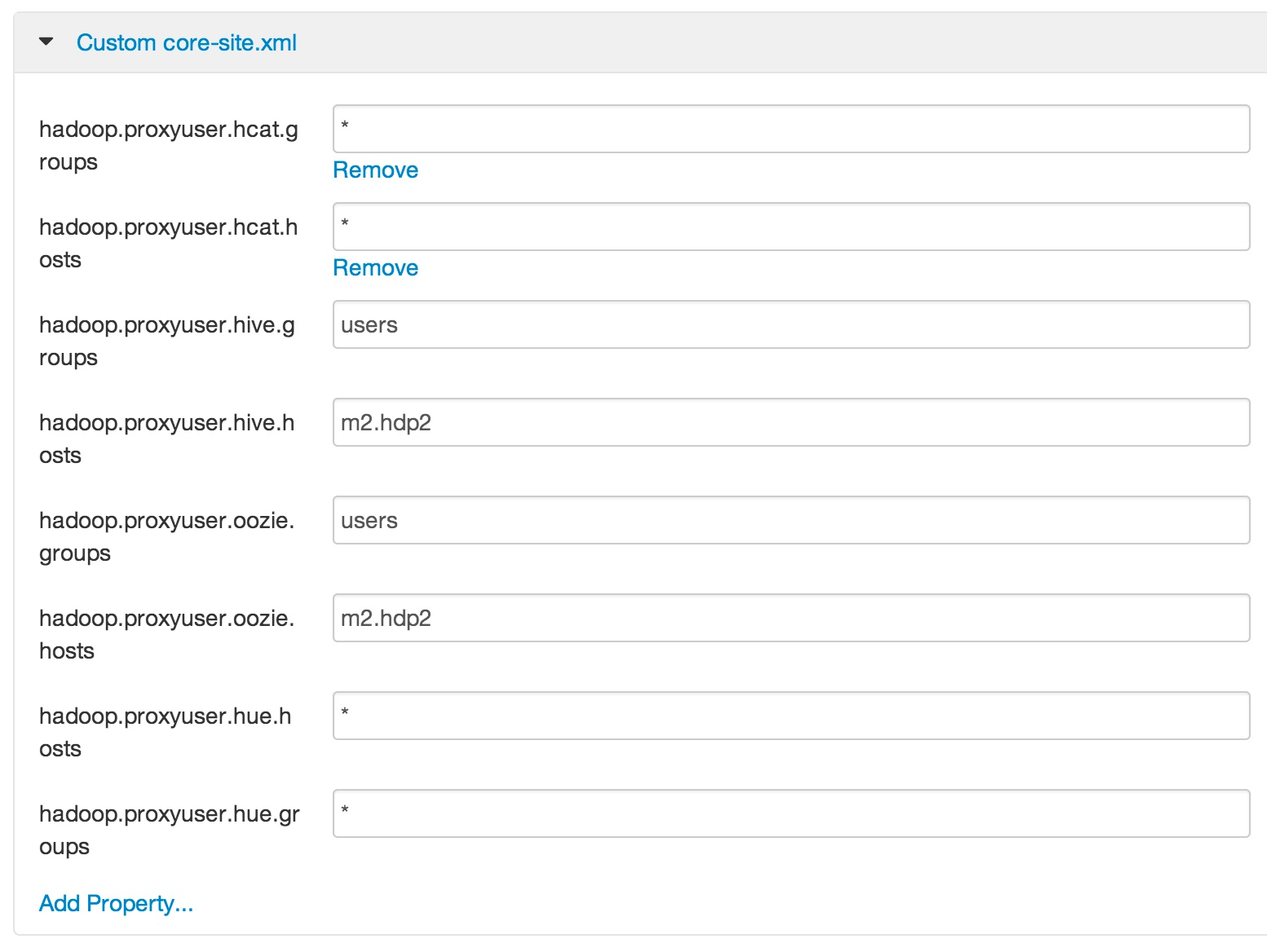 I then used Ambari to add the
I then used Ambari to add the ...hue.hosts and ...hue.groups custom properties for the webhcat-site.xml and oozie-site.xml conf files. That took us to the Install Hue instructions which I decided to run on my first master node and completed without problems. When you get to Configure Web Server steps 1-3 don't really require any action (remember, we're building a sandbox within a machine not a production ready cluster). Step 4 was a tiny bit confusing, so I'm dumping my screen in case it helps.
[root@m1 conf]# cd /usr/lib/hue/build/env/bin [root@m1 bin]# ./easy_install pyOpenSSL Searching for pyOpenSSL Best match: pyOpenSSL 0.13 Processing pyOpenSSL-0.13-py2.6-linux-x86_64.egg pyOpenSSL 0.13 is already the active version in easy-install.pth Using /usr/lib/hue/build/env/lib/python2.6/site-packages/pyOpenSSL-0.13-py2.6-linux-x86_64.egg Processing dependencies for pyOpenSSL Finished processing dependencies for pyOpenSSL [root@m1 bin]# vi /etc/hue/conf [root@m1 bin]# vi /etc/hue/conf/hue.ini ... MAKE THE CHANGES IN STEP 4-B ((I ALSO MADE A COPY OF THE .INI FILE FOR COMPARISON)) ... [root@m1 bin]# diff /etc/hue/conf/hue.ini.orig /etc/hue/conf/hue.ini 70c70 < ## ssl_certificate= --- > ## ssl_certificate=$PATH_To_CERTIFICATE 73c73 < ## ssl_private_key= --- > ## ssl_private_key=$PATH_To_KEY [root@m1 bin]# openssl genrsa 1024 > host.key Generating RSA private key, 1024 bit long modulus .........................................................................++++++ ...................................................................++++++ e is 65537 (0x10001) [root@m1 bin]# openssl req -new -x509 -nodes -sha1 -key host.key > host.cert You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [XX]:US State or Province Name (full name) []:Georgia Locality Name (eg, city) [Default City]:Alpharetta Organization Name (eg, company) [Default Company Ltd]:Hortonworks Organizational Unit Name (eg, section) []: Common Name (eg, your name or your server's hostname) []:m1.hdp2 Email Address []:lmartin@hortonworks.com [root@m1 bin]#
For sections 4.2 through 4.6 it looks like there was at least one problem (namely hadoop_hdfs_home) so I've dumped my screen again. The following is aligned with the 5-node cluster I did previously.
[root@m1 bin]# cd /etc/hue/conf [root@m1 conf]# vi hue.ini ... MAKE THE CHANGES IN STEP 4.2 - 4.6 ((I ALSO MADE A COPY OF THE .INI FILE FOR COMPARISON)) ... [root@m1 conf]# diff hue.ini.orig hue.ini 70c70 < ## ssl_certificate= --- > ## ssl_certificate=$PATH_To_CERTIFICATE 73c73 < ## ssl_private_key= --- > ## ssl_private_key=$PATH_To_KEY 238c238 < fs_defaultfs=hdfs://localhost:8020 --- > fs_defaultfs=hdfs://m1.hdp2:8020 243c243 < webhdfs_url=http://localhost:50070/webhdfs/v1/ --- > webhdfs_url=http://m1.hdp2:50070/webhdfs/v1/ 251c251 < ## hadoop_hdfs_home=/usr/lib/hadoop/lib --- > ## hadoop_hdfs_home=/usr/lib/hadoop-hdfs 298c298 < resourcemanager_host=localhost --- > resourcemanager_host=m2.hdp2 319c319 < resourcemanager_api_url=http://localhost:8088 --- > resourcemanager_api_url=http://m2.hdp2:8088 322c322 < proxy_api_url=http://localhost:8088 --- > proxy_api_url=http://m2.hdp2:8088 325c325 < history_server_api_url=http://localhost:19888 --- > history_server_api_url=http://m2.hdp2:19888 328c328 < node_manager_api_url=http://localhost:8042 --- > node_manager_api_url=http://m2.hdp2:8042 338c338 < oozie_url=http://localhost:11000/oozie --- > oozie_url=http://m2.hdp2:11000/oozie 377c377 < ## beeswax_server_host=<FQDN of Beeswax Server> --- > ## beeswax_server_host=m2.hdp2 529c529 < templeton_url="http://localhost:50111/templeton/v1/" --- > templeton_url="http://m2.hdp2:50111/templeton/v1/"
The Start Hue directions yielded the following output.
[root@m1 conf]# /etc/init.d/hue start Detecting versions of components... HUE_VERSION=2.3.0-101 HDP=2.0.6 Hadoop=2.2.0 HCatalog=0.12.0 Pig=0.12.0 Hive=0.12.0 Oozie=4.0.0 Ambari-server=1.4.3 HBase=0.96.1 Starting hue: [ OK ]
The instructions then go to Validate Configuration, but since we stopped everything with Ambari earlier it is a great time to start up all the services before going to Hue URL which for me is http://192.168.56.41:8000.
For reasons that will take longer to explain than I want to go into during this posting, when replacing 'YourHostName' in http://YourHostName:8000 to pull up Hue be sure to use a host name (or just the ip address) that all nodes within the cluster can access the node that Hue is running on. Buy me a Dr Pepper and I'll tell you all about it.
If you configured (or actually left the default configuration as it was) authentication like I did you will get this reminder when Hue comes up for the first time.

To keep my life easy, I just use hue and hue for the username and password. I also ran a dir listing on HDFS before I logged in and after as shown below. Notice that /user/hue was created after I logged in (group is hue as well).
[root@m1 ~]# su hdfs [hdfs@m1 root]$ hadoop fs -ls /user Found 5 items drwxrwx--- - ambari-qa hdfs 0 2014-04-08 19:24 /user/ambari-qa drwxr-xr-x - hcat hdfs 0 2014-01-20 00:23 /user/hcat drwx------ - hdfs hdfs 0 2014-03-20 23:00 /user/hdfs drwx------ - hive hdfs 0 2014-01-20 00:23 /user/hive drwxrwxr-x - oozie hdfs 0 2014-01-20 00:25 /user/oozie [hdfs@m1 root]$ [hdfs@m1 root]$ hadoop fs -ls /user Found 6 items drwxrwx--- - ambari-qa hdfs 0 2014-04-08 19:24 /user/ambari-qa drwxr-xr-x - hcat hdfs 0 2014-01-20 00:23 /user/hcat drwx------ - hdfs hdfs 0 2014-03-20 23:00 /user/hdfs drwx------ - hive hdfs 0 2014-01-20 00:23 /user/hive drwxr-xr-x - hue hue 0 2014-04-08 19:29 /user/hue drwxrwxr-x - oozie hdfs 0 2014-01-20 00:25 /user/oozie
My Hue UI came up fine without any misconfiguration detected so I decided to run through some of my prior blog postings to check things out. I selected how do i load a fixed-width formatted file into hive? (with a little help from pig) since it exercises Pig and Hive pretty quick.
For some reason, I could not get away with using the simple way to register the piggybank jar file shown in that quick tutorial. I had to actually load it to HDFS, I put it at /user/hue/jars/piggybank.jar, then register as shown below and explained in more detail in the comments section of create and share a pig udf (anyone can do it).
REGISTER /user/hue/jars/piggybank.jar; --that is an HDFS path
I got into trouble when I ran convert-emp and Hue's Pig interface complained for me to "Please initialize HIVE_HOME". You may not run into this problem yourself as the fix (which I actually got help from Hortonworks Support on as seen in Case_00004924.pdf) was simply to add the Hive Client to all nodes within the cluster (this will be fixed in HDP 2.1). As the ticket said, that would be painful if I had to do for tons of nodes, especially with the version of Ambari I'm using that does not yet allow you to do operations like this one many machines at a time. That said, I just needed to add it to three workers via the Ambari feature show below.
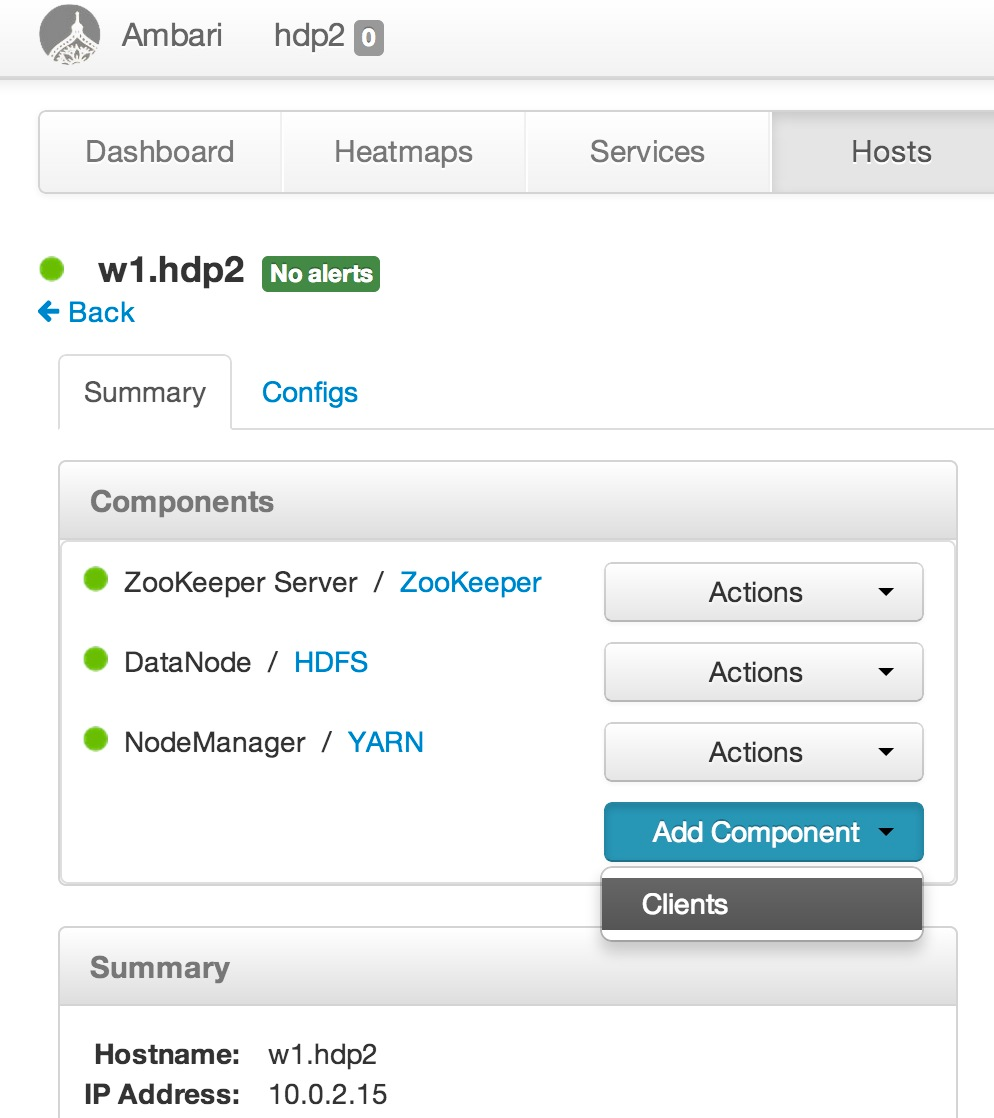
Truthfully, on my little virtualized cluster this takes a few minutes for each host. It will be nice when stuff like this can happen in parallel. Hey... just another reason to add "Clients" to all nodes in the cluster!
All in all, a bit more arduous than it ought to be, but now you have Hue running in your very own virtualized cluster!!