For the 50-ish folks that made it out to the 7/28 Atlanta .NET User Group meeting, thanks for making me feel so welcome. I know we went from 0 to 100 in an incredibly short period of time and were only able to go an inch deep and a quarter mile wide in this open-source collection of technologies, but I'm hopeful my title was appropriate and that I was able to "demystify" Hadoop some for everyone.
As promised, I wanted to make sure the content we reviewed together is available should you want to continue on your Hadoop journey.
- The presentation is available on Slideshare (in case the previewer above isn't working).
- The source code we reviewed is available in my hadoop-exploration github project.
- Help with getting VS working with HDP for Windows is available in hadoop streaming with .net map reduce api (executing on hdp for windows).
- Details on the "interesting use case" we explored can be found at Open Georgia Analysis.
If installing hdp on windows (and then running something on it) is a bit more than you're ready to get started with, just download the Hortonworks Sandbox to get started quickly and check out the tutorials, too.
Don't hesitate to use the comments section below to let me know how the presentation went and if I can help clear up anything we discussed.
This blog post is for anyone who would like some help with creating/executing a simple MapReduce job with C# – specifically for use with HDP for Windows. For my Hadoop instance, I'm using the virtual machine I had fun during my installing hdp on windows (and then running something on it) effort. As this non-JVM language will ultimately require the use of Hadoop Streaming, the ultimate goal is to use the Microsoft .NET SDK for Hadoop (specifically the Map/Reduce project) to abstract away from some of the lower-level activities. So, let's do it!
Development Environment
First up I needed an IDE; remember, I live on my Mac and I prefer to use IntelliJ. I downloaded Visual Studio Express; specifically I installed Express 2013 for Windows Desktop. After creating a new project, I needed to pull in the Hadoop SDK and kudos to NuGet as I was impressed how smooth this has become since the last time I was programming in VS. The following YouTube video shows you how to do that if it is new to you.
That video is pretty helpful and if you watched it you should already be feeling pretty good about what you are about to do. Interestingly enough, it was a MapReduce tutorial and the presenter decided to only show a Map-only job. Not wrong, but surely interesting. Don't worry... we're going to do BOTH Map AND Reduce phases! ![]()
Actually, we'll need at least three classes since we'll need a class to be the job that kicks off the MapReduce job. For our use case, we'll go back to Square-1 and implement the old "Word Count" quintessential example. For anyone not familiar with it, we want to count words in a body of text such as the Shakespeare's Sonnets. Now that we have some test data, let's get into the code.
Writing The Code
These source files can be retrieve from GitHub at https://github.com/lestermartin/hadoop-exploration/tree/master/src/main/csharp/wordcount
Mapper
The Hadoop SDK gives us a class called MapperBase that delivers to us a line at a time from the input data along with a MapperContext object that we can use to emit back our 0..n KVPs for the Mapper contract. The code below show a simple implementation of this activity.
using Microsoft.Hadoop.MapReduce;
using System;
using System.Collections.Generic;
namespace HadoopExploration
{
public class WordMapper : MapperBase
{
public override void Map(string inputLine, MapperContext context)
{
char[] delimiterChars = { ' ', ',', '.', ':', '\t' };
//split up the passed in line
string[] individualWords = inputLine.Trim().Split(delimiterChars);
//write output KVP for each one of these
foreach (string word in individualWords)
{
context.EmitKeyValue(word.ToLower(), "1");
}
}
}
}
Reducer
Like with the Mapper, we get a helper class with ReducerCombinerBase (for those who already know what a Combiner is, the name tells you all you need to know). Just like in a Java Reducer class, we are guaranteed to get the full list of values for a particular key coming from all the Mapper instances.
using Microsoft.Hadoop.MapReduce;
using System;
using System.Collections.Generic;
namespace HadoopExploration
{
public class SumReducer : ReducerCombinerBase
{
public override void Reduce(string key, IEnumerable<string> values, ReducerCombinerContext context)
{
int wordCount = 0;
//iterate through the count values passed to us by the mapper
foreach (string countAsString in values)
{
wordCount += Int32.Parse(countAsString);
}
//write output "answer" as a KVP
context.EmitKeyValue(key, Convert.ToString(wordCount));
}
}
}
You might have noticed that the helper Mapper and Reducer helper classes were pegged to just using string and do not offer the richer choices you get with Java. That makes sense considering these are still leveraging Streaming under the covers which is limited to this since it uses stdin and stdout to execute this code.
Job
As you can see with earlier video, content from SDK project, and other search results such as Bryan Smith's tutorial, there is some information out there, but it is all tailored to using HD Insights. As I said at the top of this post, I wanted to run this locally with HDP for Windows and despite the fact that HD Insights utilizes HDP I had a lot of trouble with this last step. Here is a mechanism of stitching together the Mapper and Reducer in the context of a Hadoop Job and is the biggest driver for me to write all of this down.
using Microsoft.Hadoop.MapReduce;
using System;
using System.Collections.Generic;
namespace HadoopExploration
{
class WordCount
{
static void Main(string[] args)
{
if (args.Length != 2)
{
throw new ArgumentException("Usage: WordCount <input path> <output folder>");
}
HadoopJobConfiguration jobConfig = new HadoopJobConfiguration()
{
InputPath = args[0],
OutputFolder = args[1],
DeleteOutputFolder = true
};
Hadoop.Connect().MapReduceJob.Execute<WordMapper, SumReducer>(jobConfig);
}
}
}
If you forgot how to add command-line parameters here is a little help.
- Right-click on the project name in the Solution Explorer
- Under Application menu item, set
HadoopExploration.WordCountas the Startup object - Under Debug menu item, add appropriate Command line arguments in the text box provided
Test It All Out
Save TypingTest.txt (is anyone old enough to remember this little line?) to your computer as a simple test file. It is just a 1000 copies of this line.
Now is the time for all good men to come to the aid of their country.
Put it somewhere in your HDFS home directory.
PS C:\HDP-Demo\WordCount> ls
Directory: C:\HDP-Demo\WordCount
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 7/27/2014 11:39 AM 70000 TypingTest.txt
PS C:\HDP-Demo\WordCount> hadoop fs -put TypingTest.txt wordcount/TypingTest.txt
PS C:\HDP-Demo\WordCount> hadoop fs -ls wordcount
Found 1 items
-rw-r--r-- 1 lester supergroup 70000 2014-07-27 21:32 /user/lester/wordcount/TypingTest.txt
Run the WordCount class VSE; don't forget to add some command-line parameters such as "wordcount/TypingTest.txt wordcount/mroutput" to get the following output.
File dependencies to include with job: [Auto-detected] C:\Users\lester\Documents\Visual Studio 2013\Projects\HadoopExploration\HadoopExploration\bin\Debug\HadoopExploration.vshost.exe [Auto-detected] C:\Users\lester\Documents\Visual Studio 2013\Projects\HadoopExploration\HadoopExploration\bin\Debug\HadoopExploration.exe [Auto-detected] C:\Users\lester\Documents\Visual Studio 2013\Projects\HadoopExploration\HadoopExploration\bin\Debug\Microsoft.Hadoop.MapReduce.dll [Auto-detected] C:\Users\lester\Documents\Visual Studio 2013\Projects\HadoopExploration\HadoopExploration\bin\Debug\Microsoft.Hadoop.WebClient.dll [Auto-detected] C:\Users\lester\Documents\Visual Studio 2013\Projects\HadoopExploration\HadoopExploration\bin\Debug\Newtonsoft.Json.dll packageJobJar: [] [/C:/hdp/hadoop/hadoop-1.2.0.1.3.0.0-0380/lib/hadoop-streaming .jar] C:\Users\lester\AppData\Local\Temp\streamjob5034462588780810117.jar tmpDir=null 14/07/27 22:43:29 INFO util.NativeCodeLoader: Loaded the native-hadoop library 14/07/27 22:43:29 WARN snappy.LoadSnappy: Snappy native library not loaded 14/07/27 22:43:29 INFO mapred.FileInputFormat: Total input paths to process : 1 14/07/27 22:43:29 INFO streaming.StreamJob: getLocalDirs(): [c:\hdp\data\hdfs\mapred\local] 14/07/27 22:43:29 INFO streaming.StreamJob: Running job: job_201407271215_0012 14/07/27 22:43:29 INFO streaming.StreamJob: To kill this job, run: 14/07/27 22:43:29 INFO streaming.StreamJob: C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0 380/bin/hadoop job -Dmapred.job.tracker=HDP13-1NODE:50300 -kill job_201407271215_0012 14/07/27 22:43:29 INFO streaming.StreamJob: Tracking URL: http://10.0.2.15:50030/jobdetails.jsp?jobid=job_201407271215_0012 14/07/27 22:43:30 INFO streaming.StreamJob: map 0% reduce 0% 14/07/27 22:43:36 INFO streaming.StreamJob: map 100% reduce 0% 14/07/27 22:43:43 INFO streaming.StreamJob: map 100% reduce 33% 14/07/27 22:43:44 INFO streaming.StreamJob: map 100% reduce 100% 14/07/27 22:43:46 INFO streaming.StreamJob: Job complete: job_201407271215_0012 14/07/27 22:43:46 INFO streaming.StreamJob: Output: hdfs:///user/lester/wordcount/mroutput
Then you can validate the MapReduce final answers.
PS C:\HDP-Demo\WordCount> hadoop fs -ls wordcount Found 2 items -rw-r--r-- 1 lester supergroup 70000 2014-07-27 21:32 /user/lester/wordcount/TypingTest.txt drwxr-xr-x - lester supergroup 0 2014-07-27 22:43 /user/lester/wordcount/mroutput PS C:\HDP-Demo\WordCount> hadoop fs -ls wordcount/mroutput Found 2 items drwxr-xr-x - lester supergroup 0 2014-07-27 22:43 /user/lester/wordcount/mroutput/_logs -rw-r--r-- 1 lester supergroup 132 2014-07-27 22:43 /user/lester/wordcount/mroutput/part-00000 PS C:\HDP-Demo\WordCount> hadoop fs -cat wordcount/mroutput/part-00000 aid 1000 all 1000 come 1000 country 1000 for 1000 good 1000 is 1000 men 1000 now 1000 of 1000 the 2000 their 1000 time 1000 to 2000
That's it! It all works!! Now (and just for fun), run it again using shakepoems.txt as the input and add a comment to the page letting me know how many times the word "ceremony" shows up. Also, don't hesitate to share any successes on your own or any questions that may come up from this post.
As usual, I'm running a bit behind on my extracurricular activities. What is it this time? Well, I'm on the hook to deliver a "Hadoop Demystified" preso/demo to the Atlanta .NET User Group in less than a week as identified here. Truth is... I've delivered this before, but this time the difference will be that I want to showcase HDP on Windows as the Hadoop Cluster I'll be utilizing. I'll also be showing Pig and Hive (nothing magical here) as well as MapReduce implemented with C# instead of Java.
So, what I really need to do tonight is get a box (pseudo-cluster is fine) rolling and verify I can, at least, execute a MapReduce job before I go any further. If (any of) that interests you, feel free to read along on my journey to get this going.
Installing HDP
For this "Classic Hadoop" presentation I will use HDP 1.3 and will use the QuickStart Single-Node Instructions; here's a follow-up external blog, too (note: as this deck also identifies, you'll need to run the 'hdfs format' instructions – this is missing from the HDP docs).
For the base OS, I'm using Windows Server 2012 and surfacing it via VirtualBox on my MacBook Pro. I allocated 8GB of ram, 50GB for the drive, and 4 cores to this VM. I set the Administrator password to "4Hadoop" (hey... I've got to write it down somewhere) and changed the Windows machine name to "HDP13-1NODE"; I called the VirtualBox VM "WS2012-HDP13-SingleNode". I had some issues with activating my (valid!) key, but these instructions helped me get going.
Once I started with the instructions, I decided to install the prereqs manually as described at http://docs.hortonworks.com/HDPDocuments/HDP1/HDP-Win-1.3.0/bk_installing_hdp_for_windows/content/win-getting-ready-2-3-2.html. I had trouble getting IE to download much of anything so I downloaded FireFox (i.e. I couldn't get IE to let me download Chrome) which then let me download the first two Microsoft installers. The C++ Redistributable Package installed fine, but the .NET 4.0 Framework installer reported it was already up to snuff and didn't need to do anything. For Java version, I went with the 1.6u31 initial recommendation. I installed Python's 2.7.8 version as C:\Software\Python27 to go with the suggested Java installation path of C:\Software\Java.
For the ports, I plugged in 135, 999-9999, and 49152-65535 to the instructions provided which I think covers (more than) everything. On the clusterproperties.txt file I only changed the HDP_LOG_DIR to be c:\hdp\logs so that everything goes under the c:\hdp directory. I moved all the extracted files from the zip (except the clusterproperties.txt file) back up into c:\HDP-Installation where my previously edited clusterproperties.txt file was then I ran the following.
msiexec /i "c:\HDP-Installation\hdp-1.3.0.0.winpkg.msi" /lv "c:\HDP-Installation\hdp.log" HDP_LAYOUT="c:\HDP-Installation\clusterproperties.txt" HDP_DIR="C:\hdp\hadoop" DESTROY_DATA="no"
I tried to run this as a user that had admin rights, but I got an error complaining that I needed "elevated" privileges so I just run it as the local administrator account which got me past this.
As referenced earlier, I then formatted HDFS as seen below.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop namenode -format 14/07/23 00:25:53 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = HDP13-1NODE/10.0.2.15 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0.1.3.0.0-0380 STARTUP_MSG: build = git@github.com:hortonworks/hadoop-monarch.git on branch (no branch) -r 4c12a850c61d98a885eba4396a 4abc145abb65c8; compiled by 'jenkins' on Tue Aug 06 19:39:01 Coordinated Universal Time 2013 STARTUP_MSG: java = 1.6.0_31 ************************************************************/ 14/07/23 00:25:53 INFO util.GSet: Computing capacity for map BlocksMap 14/07/23 00:25:53 INFO util.GSet: VM type = 64-bit 14/07/23 00:25:53 INFO util.GSet: 2.0% max memory = 3817799680 14/07/23 00:25:53 INFO util.GSet: capacity = 2^23 = 8388608 entries 14/07/23 00:25:53 INFO util.GSet: recommended=8388608, actual=8388608 14/07/23 00:25:53 INFO namenode.FSNamesystem: fsOwner=Administrator 14/07/23 00:25:53 INFO namenode.FSNamesystem: supergroup=supergroup 14/07/23 00:25:53 INFO namenode.FSNamesystem: isPermissionEnabled=false 14/07/23 00:25:53 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 14/07/23 00:25:53 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLi fetime=0 min(s) 14/07/23 00:25:53 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0 14/07/23 00:25:53 INFO namenode.NameNode: Caching file names occuring more than 10 times 14/07/23 00:25:53 INFO util.GSet: Computing capacity for map INodeMap 14/07/23 00:25:53 INFO util.GSet: VM type = 64-bit 14/07/23 00:25:53 INFO util.GSet: 1.0% max memory = 3817799680 14/07/23 00:25:53 INFO util.GSet: capacity = 2^22 = 4194304 entries 14/07/23 00:25:53 INFO util.GSet: recommended=4194304, actual=4194304 14/07/23 00:25:53 INFO common.Storage: Image file of size 172 saved in 0 seconds. 14/07/23 00:25:53 INFO namenode.FSEditLog: closing edit log: position=4, editlog=c:\hdp\data\hdfs\nn\current\edits 14/07/23 00:25:53 INFO namenode.FSEditLog: close success: truncate to 4, editlog=c:\hdp\data\hdfs\nn\current\edits 14/07/23 00:25:53 INFO common.Storage: Storage directory c:\hdp\data\hdfs\nn has been successfully formatted. 14/07/23 00:25:53 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at HDP13-1NODE/10.0.2.15 ************************************************************/
I then ran the 'start all' script.
PS C:\hdp\hadoop> .\start_local_hdp_services.cmd starting namenode starting secondarynamenode starting datanode starting jobtracker starting historyserver starting tasktracker starting zkServer starting master starting regionserver starting hwi starting hiveserver starting hiveserver2 starting metastore starting derbyserver starting templeton starting oozieservice Sent all start commands. total services 16 running services 16 not yet running services 0 Failed_Start PS C:\hdp\hadoop>
Despite the weird "failed" message, the counts above aligned with what I saw on the Services console; all 16 of these started as shown below.
Smoke Tests
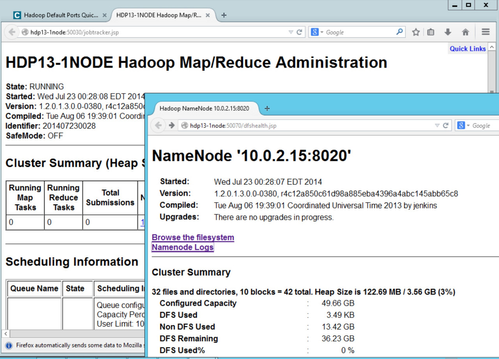
The smoke-tests failed pretty miserably as you see by checking out smokeTestFailures.txt, so I decided to take a slightly different tact to see if all is working well. I was able to pull up the trusty old UIs for JobTracker and NameNode on ports 50030 and 50070 (respectively) which was a good sign.
I added the "and then running something on it" to this blog post's title as this is where all the documentation I could find on the net stops. I didn't have luck finding a tutorial that actually did something other than declare it was installed. I'm now realizing I had more work cut out for me during this (already) late night on the computer.
To keep marching, I decided to see what would happen if I (logged in as "Administrator") tried to put some content into HDFS.
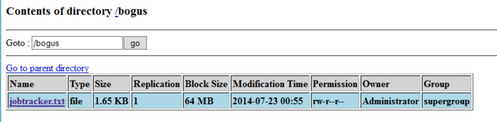
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls / Found 2 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -mkdir /bogus PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls / Found 3 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 00:53 /bogus drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -put jobtracker.xml /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /bogus Found 1 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -cat /bogus/jobtracker.txt <service> <id>jobtracker</id> <name>jobtracker</name> <description>This service runs Isotope jobtracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-server -Xmx4096m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-jobtracker-HDP13-1NODE.log -Dhadoop.home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C: \hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop.policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\conf;C:\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3 .0.0-0380\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar ;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hado op-core.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1. 3.0.0-0380\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\ hadoop-tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org .apache.hadoop.mapred.JobTracker</arguments> </service>
Awesome; it worked! As expected, my new directory & file did show up with the correct username as the owner. Also as expected, this shows up in the NameNode UI.
Typical (or not so?) User
As we shouldn't typically run things as a 'Administrator', I then logged into the Windows box as a user called 'lester' who happens to have administrator rights. I then did much of the same activities as done earlier (i.e. exploring a bit) with the FS Shell.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls / Found 3 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 00:55 /bogus drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /bogus Found 1 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -cat /bogus/jobtracker.txt <service> <id>jobtracker</id> <name>jobtracker</name> <description>This service runs Isotope jobtracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-server -Xmx4096m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-jobtracker-HDP13-1NODE.log -Dhadoop.home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C: \hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop.policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\conf;C:\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3 .0.0-0380\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar ;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hado op-core.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1. 3.0.0-0380\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\ hadoop-tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org .apache.hadoop.mapred.JobTracker</arguments> </service> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -put tasktracker.xml /bogus/tasktracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /bogus Found 2 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt -rw-r--r-- 1 lester supergroup 1688 2014-07-23 01:20 /bogus/tasktracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -cat /bogus/tasktracker.txt <service> <id>tasktracker</id> <name>tasktracker</name> <description>This service runs Isotope tasktracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-Xmx512m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-tasktracker-HDP13-1NODE.log -Dhadoop .home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C:\hdp\had oop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop .policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\conf;C :\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-03 80\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\h adoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test.jar;C:\h dp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-t ools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org.apache. hadoop.mapred.TaskTracker</arguments> </service>
Bonus points to whomever tests out what happens when another user, who does not have local admin rights, does this same thing (i.e. what group would be aligned with the directories/files). For the purposes of my (initial) testing, and taking in account what time it is, let's move on as I am able to add files. We can also stop moving files into HDFS with the CLI since we're talking about folks on Windows who probably would prefer a GUI similar to the File Exploder. Red Gate's HDFS Explorer seems to do the trick (use the "Windows authentication" option and point to the hostname for the "Cluster address" during the setup).
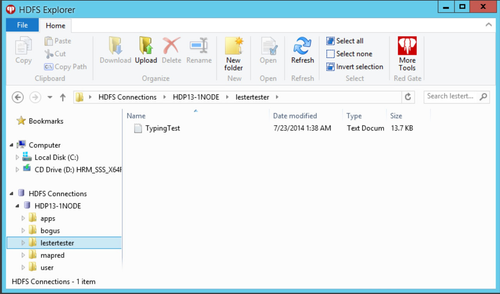
I actually expected to see the owner as 'lester' below instead of 'webuser', but again bonus points for running this down. For now, we can just march on as there doesn't seem to be any issue with the CLI tools utilizing these same files.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls / Found 4 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 01:20 /bogus drwxr-xr-x - webuser supergroup 0 2014-07-23 01:39 /lestertester drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /lestertester Found 1 items -rwxr-xr-x 1 webuser supergroup 14058 2014-07-23 01:39 /lestertester/TypingTest.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -rm /lestertester/TypingTest.txt Moved to trash: hdfs://HDP13-1NODE:8020/lestertester/TypingTest.txt
Tera Gen & Sort
Great, we can create content, so let's see if we can run Teragen and Terasort; and get myself tucked into bed!!
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop jar ..\hadoop-examples.jar teragen 1000 /lestertester/sort1000/ input Generating 1000 using 2 maps with step of 500 14/07/23 02:13:34 INFO mapred.JobClient: Running job: job_201407230028_0001 14/07/23 02:13:35 INFO mapred.JobClient: map 0% reduce 0% 14/07/23 02:13:47 INFO mapred.JobClient: map 100% reduce 0% 14/07/23 02:13:48 INFO mapred.JobClient: Job complete: job_201407230028_0001 14/07/23 02:13:48 INFO mapred.JobClient: Counters: 19 14/07/23 02:13:48 INFO mapred.JobClient: Job Counters 14/07/23 02:13:48 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6644 14/07/23 02:13:48 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/07/23 02:13:48 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/07/23 02:13:48 INFO mapred.JobClient: Launched map tasks=2 14/07/23 02:13:48 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0 14/07/23 02:13:48 INFO mapred.JobClient: File Input Format Counters 14/07/23 02:13:48 INFO mapred.JobClient: Bytes Read=0 14/07/23 02:13:48 INFO mapred.JobClient: File Output Format Counters 14/07/23 02:13:48 INFO mapred.JobClient: Bytes Written=100000 14/07/23 02:13:48 INFO mapred.JobClient: FileSystemCounters 14/07/23 02:13:48 INFO mapred.JobClient: HDFS_BYTES_READ=164 14/07/23 02:13:48 INFO mapred.JobClient: FILE_BYTES_WRITTEN=113650 14/07/23 02:13:48 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=100000 14/07/23 02:13:48 INFO mapred.JobClient: Map-Reduce Framework 14/07/23 02:13:48 INFO mapred.JobClient: Map input records=1000 14/07/23 02:13:48 INFO mapred.JobClient: Physical memory (bytes) snapshot=177201152 14/07/23 02:13:48 INFO mapred.JobClient: Spilled Records=0 14/07/23 02:13:48 INFO mapred.JobClient: CPU time spent (ms)=390 14/07/23 02:13:48 INFO mapred.JobClient: Total committed heap usage (bytes)=257294336 14/07/23 02:13:48 INFO mapred.JobClient: Virtual memory (bytes) snapshot=385998848 14/07/23 02:13:48 INFO mapred.JobClient: Map input bytes=1000 14/07/23 02:13:48 INFO mapred.JobClient: Map output records=1000 14/07/23 02:13:48 INFO mapred.JobClient: SPLIT_RAW_BYTES=164 PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /lestertester/sort1000/input Found 3 items drwxr-xr-x - lester supergroup 0 2014-07-23 02:13 /lestertester/sort1000/input/_logs -rw-r--r-- 1 lester supergroup 50000 2014-07-23 02:13 /lestertester/sort1000/input/part-00000 -rw-r--r-- 1 lester supergroup 50000 2014-07-23 02:13 /lestertester/sort1000/input/part-00001 PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop jar ..\hadoop-examples.jar terasort /lestertester/sort1000/inpu t /lestertester/sort1000/output 14/07/23 02:16:44 INFO terasort.TeraSort: starting 14/07/23 02:16:44 INFO mapred.FileInputFormat: Total input paths to process : 2 14/07/23 02:16:44 INFO util.NativeCodeLoader: Loaded the native-hadoop library 14/07/23 02:16:44 WARN snappy.LoadSnappy: Snappy native library not loaded 14/07/23 02:16:44 WARN zlib.ZlibFactory: Failed to load/initialize native-zlib library 14/07/23 02:16:44 INFO compress.CodecPool: Got brand-new compressor Making 1 from 1000 records Step size is 1000.0 14/07/23 02:16:45 INFO mapred.FileInputFormat: Total input paths to process : 2 14/07/23 02:16:45 INFO mapred.JobClient: Running job: job_201407230028_0002 14/07/23 02:16:46 INFO mapred.JobClient: map 0% reduce 0% 14/07/23 02:16:51 INFO mapred.JobClient: map 100% reduce 0% 14/07/23 02:16:58 INFO mapred.JobClient: map 100% reduce 33% 14/07/23 02:16:59 INFO mapred.JobClient: map 100% reduce 100% 14/07/23 02:17:00 INFO mapred.JobClient: Job complete: job_201407230028_0002 14/07/23 02:17:00 INFO mapred.JobClient: Counters: 30 14/07/23 02:17:00 INFO mapred.JobClient: Job Counters 14/07/23 02:17:00 INFO mapred.JobClient: Launched reduce tasks=1 14/07/23 02:17:00 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=4891 14/07/23 02:17:00 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/07/23 02:17:00 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/07/23 02:17:00 INFO mapred.JobClient: Launched map tasks=2 14/07/23 02:17:00 INFO mapred.JobClient: Data-local map tasks=2 14/07/23 02:17:00 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8217 14/07/23 02:17:00 INFO mapred.JobClient: File Input Format Counters 14/07/23 02:17:00 INFO mapred.JobClient: Bytes Read=100000 14/07/23 02:17:00 INFO mapred.JobClient: File Output Format Counters 14/07/23 02:17:00 INFO mapred.JobClient: Bytes Written=100000 14/07/23 02:17:00 INFO mapred.JobClient: FileSystemCounters 14/07/23 02:17:00 INFO mapred.JobClient: FILE_BYTES_READ=102395 14/07/23 02:17:00 INFO mapred.JobClient: HDFS_BYTES_READ=100230 14/07/23 02:17:00 INFO mapred.JobClient: FILE_BYTES_WRITTEN=379949 14/07/23 02:17:00 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=100000 14/07/23 02:17:00 INFO mapred.JobClient: Map-Reduce Framework 14/07/23 02:17:00 INFO mapred.JobClient: Map output materialized bytes=102012 14/07/23 02:17:00 INFO mapred.JobClient: Map input records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Reduce shuffle bytes=102012 14/07/23 02:17:00 INFO mapred.JobClient: Spilled Records=2000 14/07/23 02:17:00 INFO mapred.JobClient: Map output bytes=100000 14/07/23 02:17:00 INFO mapred.JobClient: Total committed heap usage (bytes)=585302016 14/07/23 02:17:00 INFO mapred.JobClient: CPU time spent (ms)=1297 14/07/23 02:17:00 INFO mapred.JobClient: Map input bytes=100000 14/07/23 02:17:00 INFO mapred.JobClient: SPLIT_RAW_BYTES=230 14/07/23 02:17:00 INFO mapred.JobClient: Combine input records=0 14/07/23 02:17:00 INFO mapred.JobClient: Reduce input records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Reduce input groups=1000 14/07/23 02:17:00 INFO mapred.JobClient: Combine output records=0 14/07/23 02:17:00 INFO mapred.JobClient: Physical memory (bytes) snapshot=477831168 14/07/23 02:17:00 INFO mapred.JobClient: Reduce output records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Virtual memory (bytes) snapshot=789450752 14/07/23 02:17:00 INFO mapred.JobClient: Map output records=1000 14/07/23 02:17:00 INFO terasort.TeraSort: done PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /lestertester/sort1000/output Found 2 items drwxr-xr-x - lester supergroup 0 2014-07-23 02:16 /lestertester/sort1000/output/_logs -rw-r--r-- 1 lester supergroup 100000 2014-07-23 02:16 /lestertester/sort1000/output/part-00000
Awesome; it works! That's enough for now as it is VERY late and I have my "day job" to think about as well. ![]()
Many people have heard of the "small files" concern with HDFS. Most think it is related to the Namenode (NN) and its memory utilization, but the NN really doesn't care much if the files it is managing are big or small -- it really is concerned about how many there are.
This topic is a fairly detailed and better described via sources such as this HDFS Scalability whitepaper, but basically it comes down to the NN needing to keep track of "objects" (i.e. in memory). These objects are directories, files and blocks. For example; if you had a tree that only had 3 top-level directories *and* each of these had 3 files *and* each of these took up 3 blocks, then your NN would need to keep track of 39 objects as detailed below.
- 3 for each of the directories
- 9 for the total number of files
- 27 for all the blocks
Now... wouldn't it be nice if Hadoop could tell you how many objects you have in place? Of course it would... and of course it does... You can run the count FS Shell operation, but that will only tell you how many directories and files are present.
[hdfs@sandbox ~]$ hdfs dfs -count /
248 510 560952712 /
One way to get the full accounting is to pull up the NN web UI.

So how much memory is required to keep track of all of these objects? It is in the neighborhood of 150-200 bytes per object, but most folks are thinking about the total number of files on a filesystem like HDFS. So if you start applying some heuristics (such as the average number of blocks per files and average files per directory) then you find yourself with the following de facto sizing guesstimate for NN memory heap size:
1 GB of heap size for every 1 million files
Again, that's not a one-size-fits-all formula, but it is a one-size-fits-MOST one that has been used rather universally with great success. Obviously, many things to consider when setting this up and just as many strategies for reducing the number of files in the first place such as concatenating files together, compressing files into a single binary (this one is most useful when the files are purely for long-term storage), leveraging Hadoop Archives, HDFS Federation, and so on. All that said, it is not uncommon to see a 96GB heap sized NN managing 100+ million files.
Not to prescribe a setting for your cluster, but at a minimum, even for early POC efforts, increase your NN heap size to, at least, 4096 MB. If using Ambari, the following screenshot shows you where to find this setting.
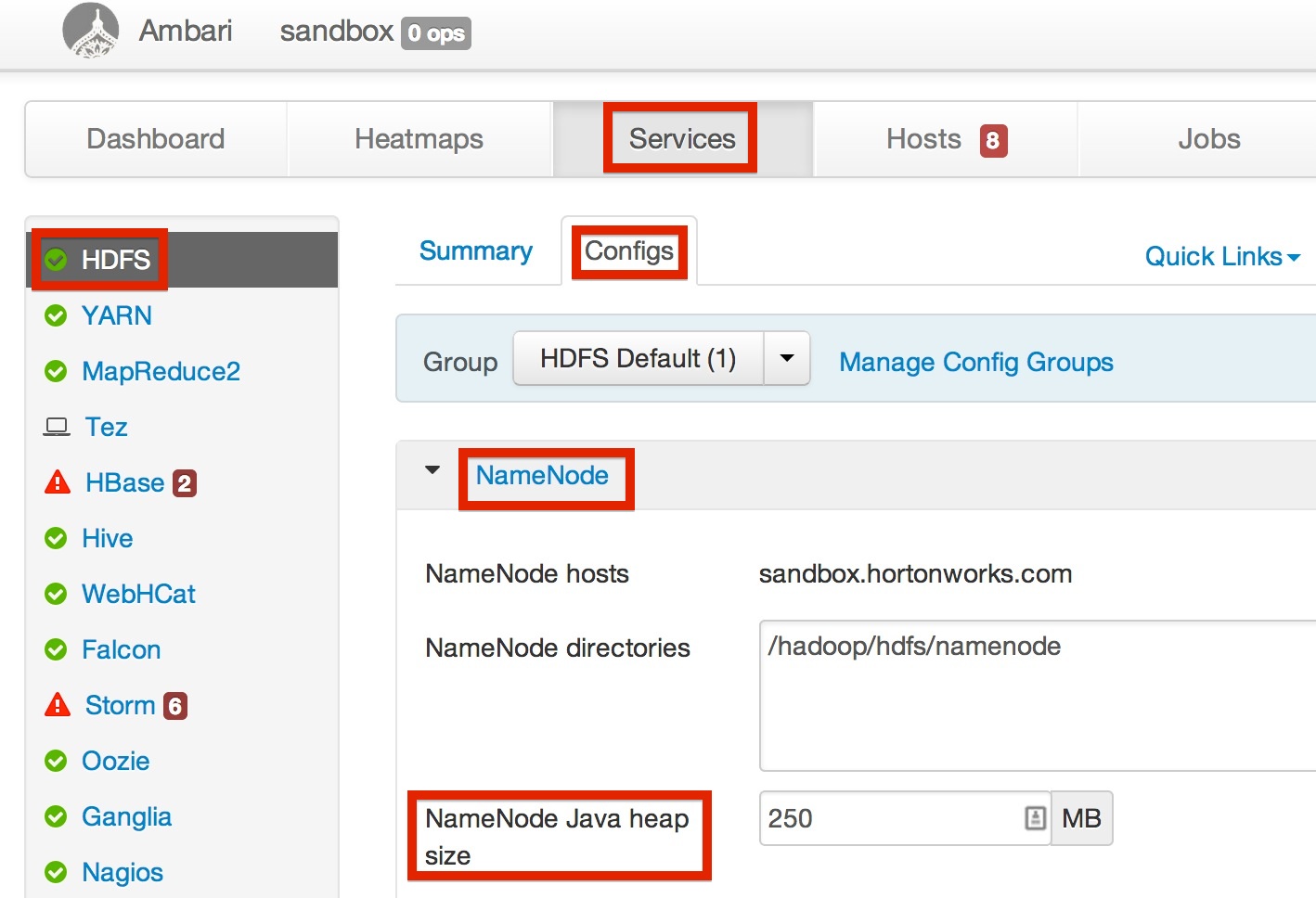
So, if we are actively monitoring our NN heap size and keeping it inline with the number of objects the NN is managing we can more accurately fine-tune our expectations for each cluster.
On the flip side, it seems easy enough to manage the amount of disk space we have on HDFS by all the inherent reporting abilities of HDFS (and tools like Ambari), not to mention some very simple math. I recently did get asked about how inodes themselves can prevent the cluster from allowing new files to be added. As a refresher, inodes keep track of all the files on a given (physical, not HDFS) file system. Here is an example of a partition that has 99% of the space allocated showing free, but the inodes are all used up.
Filesystem 1K-blocks Used Available Use% Mounted on /dev/sdf1 3906486416 10586920 3700550300 1% /data04 Filesystem Inodes IUsed IFree IUse% Mounted on /dev/sdf1 953856 953856 0 100% /data04
I'll save a richer description on inodes, pros/cons to increasing this value, and the actual procedure(s) to utilize for a stronger linux administrator than I, but again, the question raised to me was; "will the inode size matter on the (underlying) hdfs file system mounts". The short answer is that, in a cluster with more than a trivial amount of Datanodes (DNs) then inodes should not cause an issue. Basically, this is because *all* of the files will be spread across all the DNs *and* each of these will have multiple physical spindles to further spread the love.
Of course, things are often more complicated when we dive deeper. First, each file will be broken up into appropriately sized blocks and then each of these will have three copies. So, our example file above with 3 blocks will need to have 9 separate physical files stored by the DNs. As you peel back the onion, you'll see there really are two files for each block stored; the block itself and then a second file that contains metadata & checksum values. In fact, it gets a tiny bit more complicated than that by the DNs needing to have a directory structure so they don't overrun a flat directory. Chapter 10 of Hadoop: The Definitive Guide (3rd Edition) has a good write up on this as you can see here which is further visualized by the abbreviated directory listing from a DN's block data below.
[hdfs@sandbox finalized]$ pwd /hadoop/hdfs/data/current/BP-1200952396-10.0.2.15-1398089695400/current/finalized [hdfs@sandbox finalized]$ ls -al total 49940 drwxr-xr-x 66 hdfs hadoop 12288 Apr 21 07:18 . drwxr-xr-x 4 hdfs hadoop 4096 Jul 3 12:33 .. -rw-r--r-- 1 hdfs hadoop 7 Apr 21 07:16 blk_1073741825 -rw-r--r-- 1 hdfs hadoop 11 Apr 21 07:16 blk_1073741825_1001.meta -rw-r--r-- 1 hdfs hadoop 42 Apr 21 07:16 blk_1073741826 -rw-r--r-- 1 hdfs hadoop 11 Apr 21 07:16 blk_1073741826_1002.meta -rw-r--r-- 1 hdfs hadoop 392124 Apr 21 07:18 blk_1073741887 -rw-r--r-- 1 hdfs hadoop 3071 Apr 21 07:18 blk_1073741887_1063.meta -rw-r--r-- 1 hdfs hadoop 1363159 Apr 21 07:18 blk_1073741888 -rw-r--r-- 1 hdfs hadoop 10659 Apr 21 07:18 blk_1073741888_1064.meta drwxr-xr-x 2 hdfs hadoop 4096 Apr 21 07:22 subdir0 drwxr-xr-x 2 hdfs hadoop 4096 Jun 3 08:45 subdir1 drwxr-xr-x 2 hdfs hadoop 4096 Apr 21 07:21 subdir63 drwxr-xr-x 2 hdfs hadoop 4096 Apr 21 07:18 subdir9
To generalize (and let's be clear... that's what I'm doing here -- just creating a rough formula to make sure we are in the right ballpark), we can say that we'll need 2.1 times the amount of inodes for each copy of a block; that's 6.3 times the number of blocks we'd expect to be loaded into HDFS to account for replication.
To start the math, let's calculate the NbrOfAvailBlocksPerCluster which is simply the inode limit per disk TIMES the number of disks in a DN TIMES the number of DNs in the cluster and then DIVIDE that number by the 6.3 value described above. For example, the following values surface for a cluster that has DNs with 10 disks each whose JBOD file system partitions can support 1 million inodes.
- 3 Datanodes = 4.7 MM blocks
- 30 Datanodes = 47.6 MM blocks
- 300 Datanodes = 476.2 MM blocks
To then know about how many files our cluster can store before running out of inodes, we need to simply divide the NbrOfAvailBlocksPerCluster by the AvgNbrBlocksPerFile we expect for a given cluster. The following numbers are coupled with the 30 node cluster identified above.
- 1 block/file = 47.6 MM files
- 2.5 blocks/file = 19.0 MM files
- 10 blocks/file = 4.7 MM files
Now, if you are immediately worried that these calculations suggest that a cluster with 30 DNs can only hold 20 MM files (using 2.5 blocks on average), then simply raise the inodes to something larger. If the inodes setting was raised to 100 MM then that same 30 DN cluster would allow for 1.9 BILLION files. If that cluster's block size was 128 MB then it would have twice as much data as the cluster could hold.
So, let's see if we can write that down in an algebraic formula. Remember, we're just thinking about inodes here -- the disk sizing calculation is MUCH easier.
NbrOfFilesInodeSettingCanSupport = ( ( InodeSettingPerDisk * NbrDisksPerDN * NbrDNs ) / ( ReplFactor * 2.1 ) ) / AvgNbrBlocksPerFile
As I'm doing this from the beach while enjoying my last full day of vacation, I challenge everyone to double-check my numbers AND MY LOGIC as the sun and the beverages are surely getting to me.