UPDATE: Feb 5, 2015
The component referred to as "XA Secure (Apache Argus)" finally settled down with its finalized open-source name and is now referred to as Apache Ranger. I've had some very positive hands-on experiences with Ranger since this blog posting was written and I am very enthusiastic about its place in the Hadoop security stack. Check out the Apache project or Hortworks product page for more information on Ranger.
There are plenty of folks who will tell you "Hadoop isn't secure!", but that's not the whole story. Yes, as Merv Adrian points out, Hadoop in its most bare-bone mode does have a number of concerns. Fortunately, like with the rest of Hadoop, software layers upon software layers come together in concert to provide various levels of security shields to address specific requirements.
Hadoop started out with no heavy thought to security. This is because there was a problem to be solved and the "users" of the earliest incarnations of Hadoop all worked together – and all trusted each other. Fortunately for all of us, especially those of us who made career bets on this technology, Hadoop acceptance and adoption has been growing by leaps and bounds which only makes security that much more important. Some of the earliest thoughts around Hadoop security was to simply "wall it off". Yep, wrap it up with network security and only let a few, trusted, folks in. Of course, then you needed to keep letting a few more folks in and from that approach of network isolation came the ever present edge node (aka gateway server, ingestion node, etc) that almost every cluster employs today. But wait... I'm getting ahead of myself.
My goal for this posting is to cover how Hadoop addresses the AAA (Authentication, Authorization, and Auditing) spectrum that is typically used to describe system security.
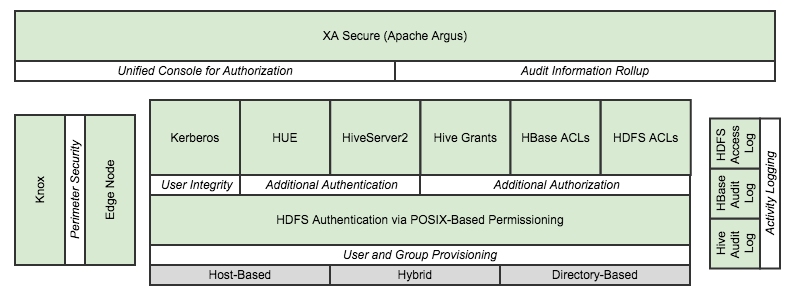 The diagram on the right represents my view of Hadoop security; well, as it is in mid-2014 as there is rapid & continuous innovation in this domain. The sections of this blog posting are oriented around the italicized characteristics in the white boxes.
The diagram on the right represents my view of Hadoop security; well, as it is in mid-2014 as there is rapid & continuous innovation in this domain. The sections of this blog posting are oriented around the italicized characteristics in the white boxes.
While the diagram presents layers, it should be clearly stated that each of these components could be utilized without dependencies on any others. The only exception to that is the base HDFS authentication that is always present and is foundational as compared to the other components. The overall security posture is enhanced by employing more (appropriate) components, but additional system complexity could be introduced into the overall system when using a component that has no direct alignment with security requirements.
For the latest on Hadoop security, please visit http://hortonworks.com/labs/security/.
User & Group Provisioning
The root of all authentication and authorization in Hadoop is based on the OS-level users and groups that people & processes are utilizing when accessing the cluster. HDFS permissions are based on the Portable Operating System Interface (POSIX) family of standards which presents a simple, but powerful file system security model: every file system object is associated with three sets of permissions that define access for the owner, the owning group, and for others. Each set may contain Read (r), Write (w), and Execute (x) permissions.
While the appropriate users and groups need to be on every host in the cluster, Hadoop is unaware of how those user/group objects were created. The primary options are as follows.
- Host-Based: This is the simplest to understand, but surely the toughest to maintain and each user and group need to be created individually on every machine. There will almost surely be security concerns around password strength & expiration and auditing as well.
- Directory-Based: In this approach a centralized resource, such as Active Directory (AD) or LDAP, is us to create users/groups and either through a commercial product or internally-development framework an integration with the hosts ensures the seamless interaction to users. This is often addressed with Pluggable Authentication Modules (PAM) integration.
- Hybrid Solution: As Hadoop is unaware of the “hows” of user/group provisioning, a custom solution could also be employed. An example could be PAM integration with AD user objects to handle authentication onto the hosts, but utilizing local groups for the authorization aspects of HDFS.
What are people doing in this space? In my experience, it seems most Hadoop systems are leveraging a hybrid approach such as the example provided for their underlying linux user & group strategy.
Where do I go for more info? http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html
User Integrity
With the pervasive reliance on identities as they are presented to the OS, Kerberos allows for even stronger authentication. Users can more reliability identify themselves and then have that identity propagated throughout the Hadoop cluster. Kerberos also secures the accounts that run the various elements in the Hadoop ecosystem thereby preventing malicious systems “posing as” part of the cluster to gain access to the data.
Kerberos can be integrated with corporate directory servers such as Microsoft's Active Directory which helps tons when there are significant number of direct Hadoop users.
What are people doing in this space? In my experience, I'd estimate that about 50% of Hadoop clusters are utilizing Kerberos. This seems to be because either the use case does not require this additional level of security and/or there is a believe that the integration & maintenance activities are too high.
Where do I go for more info? http://hortonworks.com/wp-content/uploads/2011/10/security-design_withCover-1.pdf
Additional Authentication
The right combination of secure users & groups, along with appropriate physical access points described later, provide a solid authentication model for users taking advantage of Command-Line Interface (CLI) tools from the Hadoop ecosystem (i.e. Hive, Pig, MapReduce, Streaming, etc). Additional access points will need to be secured as well. These access points could include the following.
- HDP Access Components
- HiveServer2 (HS2): Provides JDBC/ODBC connectivity to Hive
- Hue: Provides a user-friendly web application to the majority of the Hadoop ecosystem tools to complement the CLI approach.
- 3rd Party Components: Tools that sit “in front” of the Hadoop cluster may use a traditional model where they connect to the Hadoop cluster via a single “system” account (ex: via JDBC) and then present their own AAA implementations.
Hue and HS2 each have multiple authentication configuration options, to include various approaches to impersonation, that can augment, or even replace, whatever approach is being leveraged by the CLI tooling environment. Additionally, 3rd party tools such as Business Objects will provide their own AAA functionality to manage existing users and utilize a system account to connect to Hive/HS2.
What are people doing in this space? Generally, it seems to me that teams are configuring authentication in these access points to be aligned with the same authentication that the CLI tools are using. Some organizations with a more narrowly-focused plan for utilization of their cluster are "locking down" access to the data from first-class Hadoop clients (FS Shell, Pig, Hive/HS2, MapReduce, etc) to only the true exploratory data science and software development communities and taking an approach from the application server playbook – having 3rd party BI/reporting tools use a "system account" to interact with relational-oriented data via HS2 and leveraging the rich AAA abilities of these user-facing tools.
Where do I go for more info? https://cwiki.apache.org/confluence/display/Hive/Setting+Up+HiveServer2 and https://github.com/cloudera/hue/blob/master/desktop/conf.dist/hue.ini
Additional Authorization
The POSIX-based permission model described earlier will accommodate most security needs, but there is an additional option should the security authorization rules become more complex than this model can handle. HDFS ACLs (Access Control Lists) have surfaced to accommodate this need. This feature became available in HDP 2.1 and is inherently available thus can be taken advantage of when the authorization use case demands it.
The long-time “data services” members of the HDP stack, HBase and Hive, also allow additional ACLs to be set on the “objects” that are present in their frameworks. For Hive, this is presented as the ability to grant/revoke access controls on tables. HBase provides authorization on tables and column families. Accumulo (another “data services” offering from HDP) extends the HBase model down to the ability to control cell-level authorization.
As a result of Hortonworks’ recent acquisition of XA Secure, the addition of a unified console for authorization across the ecosystem offerings has become available. The maturity of this product, which is actively being spun into the new incubating project called Apache Argus, should greatly help its eventual promotion to a top-level Apache project.
What are people doing in this space? Those already using HBase are leveraging its features as appropriate to their projects, but HDFS ACLs and Hive's ATZ-NG are still gaining adoption due to their relatively recent introductions.
Where do I go for more info? http://hbase.apache.org/book/hbase.accesscontrol.configuration.html, https://cwiki.apache.org/confluence/display/Hive/SQL+Standard+Based+Hive+Authorization, http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.5/bk_system-admin-guide/content/ch_acls-on-hdfs.html and http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.3/bk_HDPSecure_Admin/content/ch_XA-overview.html
Activity Logging
HDFS has a built in ability to log access requests to the filesystem. This provides a low-level snapshot of events that occur and who did them. These are human-readable, but not necessarily reader-friendly. They are detailed logs that can themselves be used as a basis for reporting and/or ad-hoc querying with Hadoop frameworks and/or other 3rd party tools.
Hive also has an ability to log metastore API invocations. Additionally, HBase offers its own audit log. To pull this all together into a single pane of glass you can leverage XA Secure / Apache Argus. This software layer pulls this dispersed audit information into a cohesive user experience. The audit data can be further broken down into access audit, policy audit and agent audit data, giving granular visibility to auditors on users’ access as well as administrative actions within this security portal.
What are people doing in this space? XA Secure / Apache Argus is early in its adoption curve, but is a feature-rich application so I do expect quick adoption of it. While the raw data is there, it seems that few organizations are currently rolling the disparate activity logs into a combined view for audit reporting.
Where do I go for more info? http://books.google.com/books?id=drbI_aro20oC&pg=PA346&lpg=PA346&dq=hdfs+audit+log&source=bl&ots=t_wnyhn0i4&sig=PEbiD5LdLdkUP0jnjhtUoOoBDMM&hl=en&sa=X&ei=YwsJVKeGDZSBygT5x4D4Cg&sqi=2&ved=0CEIQ6AEwAg#v=onepage&q=hdfs%20audit%20log&f=false and http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.3/bk_HDPSecure_Admin/content/ch_XA-audit.html
Perimeter Security
As mentioned at the beginning of this post, establishing perimeter security has been a foundational Hadoop security approach. This is simply viewed as having limited access into the Hadoop cluster itself and utilizing an “edge” node (aka gateway) as a host users and systems can utilize directly and then have all other actions fired from this gateway into the cluster itself.
The Apache Knox gateway provides a software layer intended to perform this perimeter security function. It has a pluggable provider based mechanism to integrate customer AAA mechanisms. Not all operations are fully supported yet with Knox to have it completely replace the need for the traditional edge node, but the project's roadmap addresses missing functionality. It's REST API extends the reach to different types of clients and eliminates the need to SSH to a fully configured "Hadoop client" to interact with the Hadoop cluster (or several as Knox can front multiple clusters).
What are people doing in this space? Early adopters have already deployed Knox, but the majority of clusters still rely heavily on traditional edge nodes. The interest is clearly present in almost all customers that I work and I expect a rapid adoption of this technology.
Where do I go for more info? http://www.dummies.com/how-to/content/edge-nodes-in-hadoop-clusters.html and http://knox.apache.org/
Data Encryption
Data encryption can be broken into two primary scenarios; encryption in-transit and encryption at-rest. Wire encryption options exist in Hadoop to aid with the in-transit needs that might be present. There are multiple options available to protect data as it moves through Hadoop over RPC, HTTP, Data Transfer Protocol (DTP), and JDBC.
For encryption at-rest, there are some open source activities underway, but Hadoop does not inherently have a baseline encryption solution for the data that is persisted within HDFS. There are several 3rd party solutions available that specifically target this requirement. Custom development could also be undertaken, but the absolute easiest mechanism to obtain encryption at-rest is to tackle this at an OS or hardware level.
What are people doing in this space? My awareness is that few Hadoop administrators have enabled encryption, at-rest or in-transit, at this time.
Where do I go for more info? http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.3/bk_reference/content/reference_chap-wire-encryption.html
Summary
As you can see, there are many avenues to explore to ensure you create the best security posture for your particular needs. Remember, the vast majority of these options are mutually exclusive allowing for multiple approaches to security. This is surely one area there still is work to be done and definitely in pulling together the disparate pieces into tools that are easy to adopt by enterprises.
These corrections were made on 9/2/2015 to this blog posting.
So... time to eat some crow. I had a customer who is automating their user onboarding process for his Hadoop cluster and wanted to know if he could use a linux account besides hdfs to create a HDFS user home directory and set the appropriate permissions – see simple hadoop cluster user provisioning process (simple = w/o pam or kerberos) . I told him he was out of luck and that was just the way it was going to be.
Thinking about it a bit later, I realized I actually never ran this one down. Navigating through the Hadoop site got me to http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html#The_Super-User which told me what I've been espousing all along; the user that starts up the NameNode (NN) is the superuser. Then I saw it – the phrase that let me know I was wrong in my reply...
In addition, the administrator may identify a distinguished group using a configuration parameter. If set, members of this group are also super-users.
Doh! I was definitely wrong in my thinking and reply to my customer. Hey, only the second time this month, but we have half a month to go!!
Let's see this in action. First, we need a test bed to work from. Let's use hdfs to create a test directory and then lock down the permissions to only the hdfs user.
[root@sandbox ~]# su hdfs [hdfs@sandbox root]$ hdfs dfs -mkdir /testSuperUser [hdfs@sandbox root]$ hdfs dfs -mkdir /testSuperUser/testDirectory [hdfs@sandbox root]$ hdfs dfs -ls /testSuperUser Found 1 items drwxr-xr-x - hdfs hdfs 0 2014-08-13 22:42 /testSuperUser/testDirectory [hdfs@sandbox root]$ hdfs dfs -chmod 700 /testSuperUser/testDirectory [hdfs@sandbox root]$ hdfs dfs -ls /testSuperUser Found 1 items drwx------ - hdfs hdfs 0 2014-08-13 22:42 /testSuperUser/testDirectory
Now let's create an animals group with two users in it; cat and bat.
[hdfs@sandbox root]$ exit exit [root@sandbox ~]# groupadd animals [root@sandbox ~]# useradd -ganimals cat [root@sandbox ~]# useradd -ganimals bat [root@sandbox ~]# lid -g animals cat(uid=1021) bat(uid=1022)
Then make sure they can't do anything that requires superuser access.
[root@sandbox ~]# su cat [cat@sandbox root]$ hdfs dfs -ls /testSuperUser Found 1 items drwx------ - hdfs hdfs 0 2014-08-13 22:42 /testSuperUser/testDirectory [cat@sandbox root]$ hdfs dfs -chgrp bogus /testSuperUser/testDirectory chgrp: changing ownership of '/testSuperUser/testDirectory': Permission denied
No joy, but that is as expected. The instructions at http://hadoop.apache.org/docs/r2.4.1/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html#Configuration_Parameters let me know I need to make sure there is a dfs.permissions.superusergroup KVP created for hdfs-site.xml. This parameter can be found in Ambari at Services > HDFS > Configs > Advanced > dfs.permissions.superusergroup. For my Hortonworks Sandbox this value is set to hdfs. This also aligns with the fact that unless you do a −chgrp, your newly created items have the group set to hdfs on this little pseudo-cluster. Contrary to what you would expect (i.e. the group becomes the value for this setting), I did find out later that even with a different superusergroup identified, the owning group stayed as hdfs.
[cat@sandbox root]$ exit exit [root@sandbox ~]# su turtle [turtle@sandbox root]$ hdfs dfs -put /etc/group groups.txt [turtle@sandbox root]$ hdfs dfs -ls Found 1 items -rw-r--r-- 1 turtle hdfs 1033 2014-08-13 23:12 groups.txt
After I changed the "superuser" group to be animals, I could then make the changes that I wanted to earlier.
[turtle@sandbox root]$ exit exit [root@sandbox ~]# su cat [cat@sandbox root]$ hdfs dfs -ls /testSuperUser Found 1 items drwx------ - hdfs hdfs 0 2014-08-13 22:42 /testSuperUser/testDirectory [cat@sandbox root]$ hdfs dfs -chgrp bogus /testSuperUser/testDirectory [cat@sandbox root]$ hdfs dfs -ls /testSuperUser Found 1 items drwx------ - hdfs bogus 0 2014-08-13 22:42 /testSuperUser/testDirectory
I also did not screw up the fact that hdfs is my true superuser as shown by my "old" HDFS home directory process.
[cat@sandbox root]$ exit exit [root@sandbox ~]# useradd user1 [root@sandbox ~]# su hdfs [hdfs@sandbox root]$ hdfs dfs -mkdir /user/user1 [hdfs@sandbox root]$ hdfs dfs -ls /user ... rm'd some lines ... NOTICE THAT THE GROUP STILL DEFAULTS TO hdfs, NOT animals drwxr-xr-x - hdfs hdfs 0 2014-08-13 23:49 /user/user1 [hdfs@sandbox root]$ hdfs dfs -chown user1 /user/user1 [hdfs@sandbox root]$ hdfs dfs -chgrp user1 /user/user1 [hdfs@sandbox root]$ hdfs dfs -ls /user ... rm'd some lines ... drwxr-xr-x - user1 user1 0 2014-08-13 23:49 /user/user1
Which can now also be done as a "real" user if set up appropriately. If bat had appropriate sudo rights, then I could have done the following without starting out at root.
[hdfs@sandbox root]$ exit exit [root@sandbox ~]# useradd user2 [root@sandbox ~]# su bat [bat@sandbox root]$ hdfs dfs -mkdir /user/user2 [bat@sandbox root]$ hdfs dfs -ls /user ... rm'd some lines ... NOTICE THAT THE GROUP STILL DEFAULTS TO hdfs, NOT animals drwxr-xr-x - user1 user1 0 2014-08-13 23:49 /user/user1 drwxr-xr-x - bat hdfs 0 2014-08-13 23:55 /user/user2 [bat@sandbox root]$ hdfs dfs -chown user2 /user/user2 [bat@sandbox root]$ hdfs dfs -chgrp user2 /user/user2 [bat@sandbox root]$ hdfs dfs -ls /user ... rm'd some lines ... drwxr-xr-x - user1 user1 0 2014-08-13 23:49 /user/user1 drwxr-xr-x - user2 user2 0 2014-08-13 23:55 /user/user2
As usual, there are many ways to skin this cat and this simple property is the gateway to those choices. For many, the simple model of just adding the desired linux user(s) to the existing "superusers" group may be the way to go. If you are using this today, or might just do so, I'd love to hear your actual, or planned, approach.