...
As described in hadoop worker node configuration recommendations (1-2-10), many cluster's worker nodes are being provisioned with 8-12 drives and this which are identified as list of directories in the dfs.datanode.data.dir property of hdfs-site.xml. This many disks introduces a class of failure that is likely to happen somewhat more frequently than general machine failure. That is hard disk failure. Consider a Hadoop cluster with 200 worker nodes each of which have 12 drives devoted to the DataNode and to provide storage to HDFS. That yields 2400 spinning disks just waiting for something bad to happen. Without going into an elaborate discussion on Mean Time Between Failures, or even Seagate's preferred AFR, it is easy enough to imagine one of these hard drives failing per week.
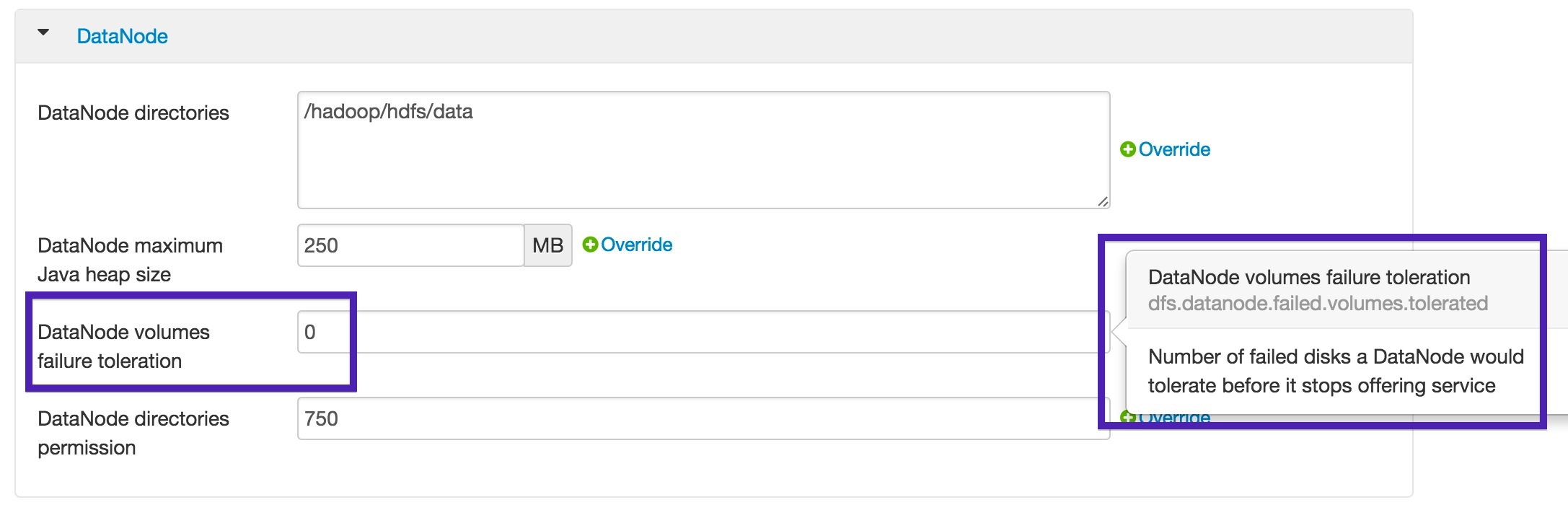
With the default settings of a straightforward Hadoop installation the , DataNode is configured toprocesses are configured to stop running once they detect any failures in any of their configured disks. This can be verified by the following stanza in hdfs-site.xml.
| Code Block | ||
|---|---|---|
| ||
<property>
<name<dfs.datanode.failed.volumes.tolerated</name>
<value>0</value>
</property> |
For those using Ambari, you can find the following UI snippet at Services > HDFS > Configs.