improving datanode resiliency (it's all about the settings)
Obviously, Hadoop's holistic set of DataNode worker services along with the NameNode master processes, especially when using HA NN configuration, provide a robust platform for HDFS to survive a failure to a worker node and for the file system to keep on keeping on. Those worker node failures can take a variety of forms (power supply out, NIC problems, controller is fried, etc) and in general it makes sense to simply build a model where you repair or replace the worker node to restore full level of service to the cluster.
As described in hadoop worker node configuration recommendations (1-2-10), many cluster's worker nodes are being provisioned with 8-12 drives which are identified as list of directories in the dfs.datanode.data.dir property of hdfs-site.xml. This many disks introduces a class of failure that is likely to happen somewhat more frequently than general machine failure. That is hard disk failure. Consider a Hadoop cluster with 200 worker nodes each of which have 12 drives devoted to the DataNode and to provide storage to HDFS. That yields 2400 spinning disks just waiting for something bad to happen. Without going into an elaborate discussion on Mean Time Between Failures, or even Seagate's preferred AFR, it is easy enough to imagine one of these hard drives failing per week.
With the default settings of a straightforward Hadoop installation, DataNode processes are configured to stop running once they detect any failures in any of their configured disks. This can be verified by the following stanza in hdfs-site.xml.
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>0</value>
</property>
For those using Ambari, you can find the following UI snippet at Services > HDFS > Configs for this setting.
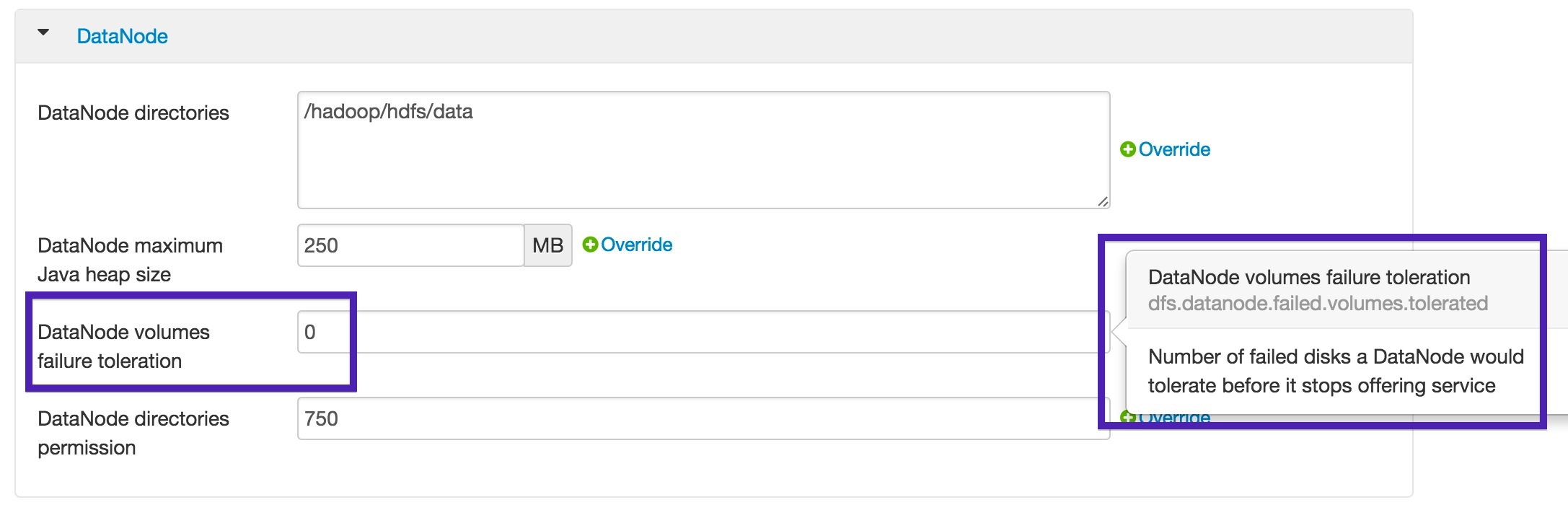
My personal recommendation; if your DataNodes are leveraging 4+ drives, set this value to approximately one-third of the number of disks as shown in the table below.
| Number of DN Drives | Drive Failure Toleranace |
|---|---|
| 4 | 1 |
| 6 | 2 |
| 8 | 2 |
| 10 | 3 |
| 12 | 4 |
The goal is surely not to try to run these worker nodes until the max value of the dfs.datanode.failed.volumes.tolerated property, but rather give the Hadoop administrator a chance to deal with this kind of hardware failure in an extremely non-critical fashion. A single failure would be enough to identify the node to be pulled out in the next rotation which might be a weekly process. That process would also allow for a graceful decommission process to occur which would make sure all the necessary blocks are fully replicated before the DataNode process shuts down. Then the box can then be repaired and ultimately brought back into the cluster.
While my example was for a decently-sized cluster, the biggest value for this modification is in much smaller clusters where the impact of a single DataNode going down is much greater. In that situation, a more dramatic decrease to the overall HDFS capacity occurs and forces a higher percentage of the DataNodes to participate in the (emergency) reallocation of blocks to restore the replication factor for each.