This is a sister post to installing hdp 2.2 with ambari 2.0 (moving to the azure cloud), but this time using AWS' EC2 IaaS servers. Just like with Azure having options such as HDInsight, AWS offers EMR for an easy to deploy Hadoop option. This post is focused on using another Cloud provider's IaaS offering to help someone who is planning on deploying the full HDP stack (in the cloud or on-prem), so I'll focus on using AWS' EC2 offering.
...
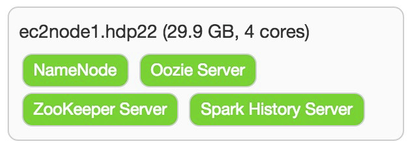
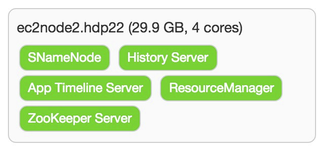
Once you click on Register and Confirm, and like with installing hdp 2.2 with ambari 2.0 (moving to the azure cloud), you will get hit with waning about the ntpd service not running. You can ignore it since it clearly looks like these EC2 instances are in lock-step on time sync. You will also be warned that Transparent Huge Pages (THP) is enabled and just ignored it because, well frankly just because this is still just a test cluster and we need to keep moving forward to wrap up the install. ![]() On the Choose Services wizard step, I deselected HBase, Sqoop, Falcon, Storm, Flume, Knox and Kafka (left in Spark – dismiss the erroneous warning pop-up) as just want to be able to still have enough resources on these multipurpose master/worker nodes. I spread out the masters servers as shown below.
On the Choose Services wizard step, I deselected HBase, Sqoop, Falcon, Storm, Flume, Knox and Kafka (left in Spark – dismiss the erroneous warning pop-up) as just want to be able to still have enough resources on these multipurpose master/worker nodes. I spread out the masters servers as shown below.

...
With the (again, not recommended!) strategy of making each node a master and a worker, I simply checked all boxes on the Assign Slaves and Clients screen. As usual, there are some things that have to be addressed on the Customize Services screen. For the Hive and Oozietabs you are required for selecting a password for each of these components. There are some other changes that need to be made. For those properties than can (and should!) support multiple directories, Ambari tries to help out. In most cases it adds the desired /grid/[1-3] mount points, but usually also brings in the "special" Azure filesystem, too. The following table identifies the properties that need some attention prior to moving forward.
...
.
...
...
ard.
| Tab | Section | Property | Action | Notes |
|---|---|---|---|---|
| HDFS | NameNode | NameNode directories | Replace all with /hadoop/hdfs/namenode | Not ideal, but we'll probable reconfigure to HA NN later |
| NameNode Java heap size | Reduce to 2048 | The much larger suggested value was a good starter place, but Ambari was imagining this node would be primarily focused on running the NameNode, but just need to be mindful this VM only has about 30GB of memory | ||
| NameNode new generation size | Reduce to 512 | Keeping inline with heap size | ||
| NameNode maximum new generation size | Reduce to 512 | Same as previous | ||
| Secondary NameNode | SecondaryNameNode Checkpoint directories | Trim down to just /hadoop/hdfs/namesecondary | Again, not ideal, but it'll get us going for now | |
| DataNode | DataNode volumes failure toleration | Increase to 1 | Allow one of the 3 drives on each worker to be unavailable and still serve as a DN | |
| YARN | Node ManagerApplication Timeline Server | yarn.nodemanager.log-dir | Remove the /mnt/resource/hadoop/yarn/log entry | |
| yarn.nodemanager.local-dirs | Remove the /mnt/resource/hadoop/yarn/local entry | |||
| Application Timeline Server | yarn.timeline-service.leveldb-timeline-store.path | Trim down to just /hadoop/yarn/timeline | ||
| Tez | General | tez.am.resource.memory.mb | Reduce to 2048 | |
| ZooKeeper | ZooKeeper Server | ZooKeeper directory | Trim down to just /hadoop/zookeeper | |
| Falcon | Falcon startup.properties | *.falcon.graph.storage.directory | Trim off leading /grid/1 path | |
| *.falcon.graph.serialize.path | Trim off leading /grid/1 path | |||
| Storm | General | storm.local.dir | Trim off leading /grid/1 path | |
| Kafka | Kafka Broker | log.dirs | Remove the /mnt/resource/kafka-logs entry |
When I finally moved passed this screen, I was presented with some warnings on a few of the changes above all focused on memory. With this primarily being a cluster build-out activity this should not be a problem for the kinds of limited workloads I'll be running on this cluster.
After the obligatory Install, Start and Test status bars finished up, I was When I finally moved passed this screen, I was presented with some warnings on a few of the changes above all focused on memory. With this primarily being a cluster build-out activity this should not be a problem for the kinds of limited workloads I'll be running on this cluster.
As the obligatory Install, Start and Test wizard wrapped up, I was blasted with orange bars of pain. I drilled into the warnings and then it hit me that all the ports listed on http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.2.6/bk_HDP_Reference_Guide/content/reference_chap2.html simply were being blocked thus preventing many things from being started up, or even more likely, from being fully registered to Ambari Metrics. I ended up making the following additional inbound port rules.
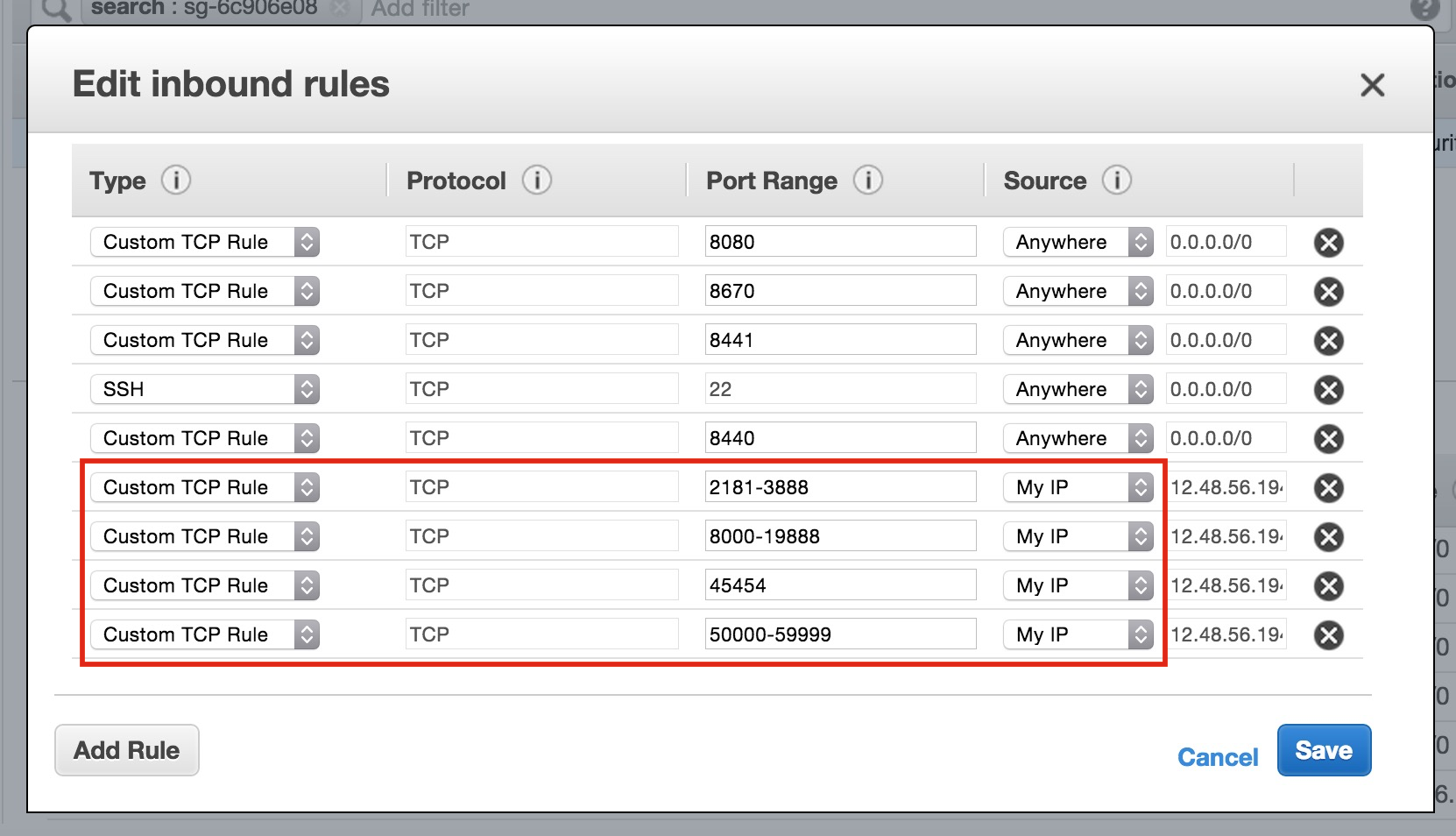
The "My IP" Source option (it automatically manages the IP column) seems to do the trick from locking out general public access, but you will still have to open up any UI or master process ports that you need to hit from outside of these EC2 instances. After I issued a Stop All and then Start All I was (finally) able to pull up Ambari.
AMBARI SCREEN GOES HERE
| Tip |
|---|
To kick the tires, I created a user with the simple hadoop cluster user provisioning process (simple = w/o pam or kerberos) and then did a hadoop mini smoke test (VERY mini) to verify the basic install is working correctly. |
With this HDP cluster running on AWS EC2 instances, I'll wrap up another Hadoop installation blog posting!!