...
For those using Ambari, you can find the following UI snippet at Services > HDFS > Configs for this setting.
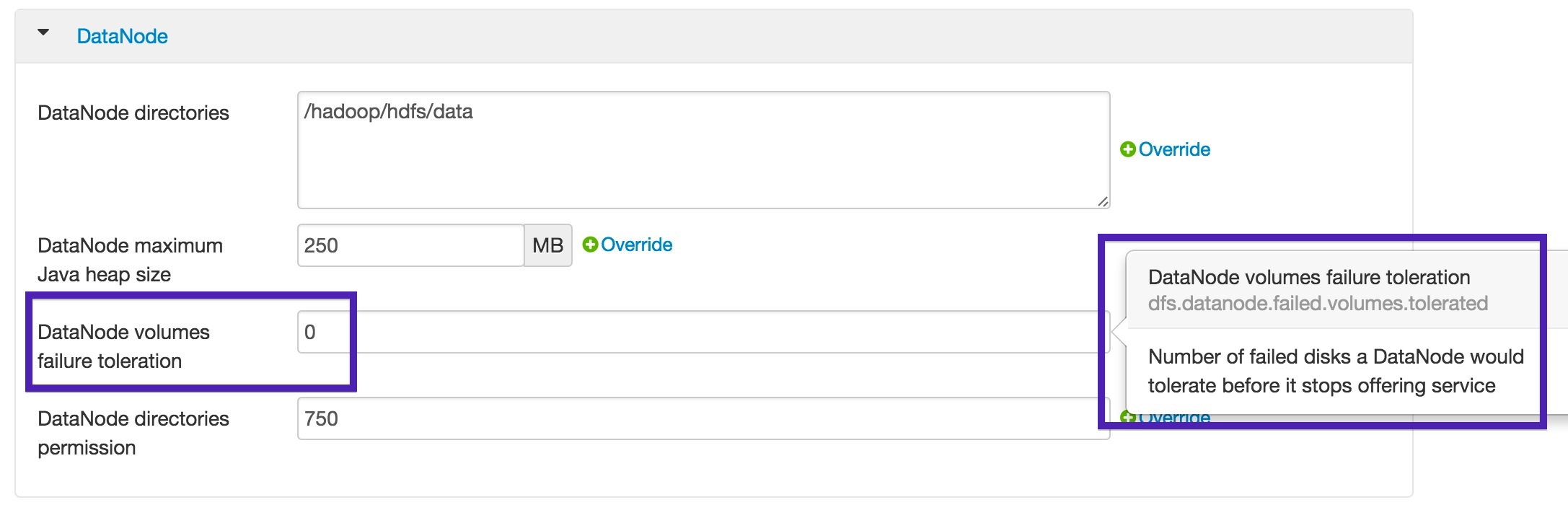
It is my My personal recommendation that ; if your DataNodes are leveraging 4+ drives to , set this value at to approximately one-third of the number of disks as shown in the table below.
...
The goal is surely not to try to run these worker nodes until the max value of the dfs.datanode.failed.volumes.tolerated property, but rather give the Hadoop administrator a chance to deal with this kind of hardware failure in an extremely non-critical fashion. A single failure would be enough to identify the node to be pulled out in the next rotation which might be a weekly process. That process would also allow for a graceful decommission process to occur which would make sure all the necessary blocks are fully replicated before the DataNode process shuts down. Then the box can then be repaired and can be ultimately brought back into the cluster.
While my example was for a decently-sized cluster, the biggest value for this modification is in much smaller clusters where the impact of a single DataNode going down is much greater. In that situation, a more dramatic decrease to the overall HDFS capacity occurs and forces a higher percentage of the DataNodes to participate in the (emergency) reallocation of blocks to restore the replication factor for each.