installing hdp on windows (and then running something on it)
As usual, I'm running a bit behind on my extracurricular activities. What is it this time? Well, I'm on the hook to deliver a "Hadoop Demystified" preso/demo to the Atlanta .NET User Group in less than a week as identified here. Truth is... I've delivered this before, but this time the difference will be that I want to showcase HDP on Windows as the Hadoop Cluster I'll be utilizing. I'll also be showing Pig and Hive (nothing magical here) as well as MapReduce implemented with C# instead of Java.
So, what I really need to do tonight is get a box (pseudo-cluster is fine) rolling and verify I can, at least, execute a MapReduce job before I go any further. If (any of) that interests you, feel free to read along on my journey to get this going.
Installing HDP
For this "Classic Hadoop" presentation I will use HDP 1.3 and will use the QuickStart Single-Node Instructions; here's a follow-up external blog, too (note: as this deck also identifies, you'll need to run the 'hdfs format' instructions – this is missing from the HDP docs).
For the base OS, I'm using Windows Server 2012 and surfacing it via VirtualBox on my MacBook Pro. I allocated 8GB of ram, 50GB for the drive, and 4 cores to this VM. I set the Administrator password to "4Hadoop" (hey... I've got to write it down somewhere) and changed the Windows machine name to "HDP13-1NODE"; I called the VirtualBox VM "WS2012-HDP13-SingleNode". I had some issues with activating my (valid!) key, but these instructions helped me get going.
Once I started with the instructions, I decided to install the prereqs manually as described at http://docs.hortonworks.com/HDPDocuments/HDP1/HDP-Win-1.3.0/bk_installing_hdp_for_windows/content/win-getting-ready-2-3-2.html. I had trouble getting IE to download much of anything so I downloaded FireFox (i.e. I couldn't get IE to let me download Chrome) which then let me download the first two Microsoft installers. The C++ Redistributable Package installed fine, but the .NET 4.0 Framework installer reported it was already up to snuff and didn't need to do anything. For Java version, I went with the 1.6u31 initial recommendation. I installed Python's 2.7.8 version as C:\Software\Python27 to go with the suggested Java installation path of C:\Software\Java.
For the ports, I plugged in 135, 999-9999, and 49152-65535 to the instructions provided which I think covers (more than) everything. On the clusterproperties.txt file I only changed the HDP_LOG_DIR to be c:\hdp\logs so that everything goes under the c:\hdp directory. I moved all the extracted files from the zip (except the clusterproperties.txt file) back up into c:\HDP-Installation where my previously edited clusterproperties.txt file was then I ran the following.
msiexec /i "c:\HDP-Installation\hdp-1.3.0.0.winpkg.msi" /lv "c:\HDP-Installation\hdp.log" HDP_LAYOUT="c:\HDP-Installation\clusterproperties.txt" HDP_DIR="C:\hdp\hadoop" DESTROY_DATA="no"
I tried to run this as a user that had admin rights, but I got an error complaining that I needed "elevated" privileges so I just run it as the local administrator account which got me past this.
As referenced earlier, I then formatted HDFS as seen below.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop namenode -format 14/07/23 00:25:53 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = HDP13-1NODE/10.0.2.15 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0.1.3.0.0-0380 STARTUP_MSG: build = git@github.com:hortonworks/hadoop-monarch.git on branch (no branch) -r 4c12a850c61d98a885eba4396a 4abc145abb65c8; compiled by 'jenkins' on Tue Aug 06 19:39:01 Coordinated Universal Time 2013 STARTUP_MSG: java = 1.6.0_31 ************************************************************/ 14/07/23 00:25:53 INFO util.GSet: Computing capacity for map BlocksMap 14/07/23 00:25:53 INFO util.GSet: VM type = 64-bit 14/07/23 00:25:53 INFO util.GSet: 2.0% max memory = 3817799680 14/07/23 00:25:53 INFO util.GSet: capacity = 2^23 = 8388608 entries 14/07/23 00:25:53 INFO util.GSet: recommended=8388608, actual=8388608 14/07/23 00:25:53 INFO namenode.FSNamesystem: fsOwner=Administrator 14/07/23 00:25:53 INFO namenode.FSNamesystem: supergroup=supergroup 14/07/23 00:25:53 INFO namenode.FSNamesystem: isPermissionEnabled=false 14/07/23 00:25:53 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 14/07/23 00:25:53 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLi fetime=0 min(s) 14/07/23 00:25:53 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0 14/07/23 00:25:53 INFO namenode.NameNode: Caching file names occuring more than 10 times 14/07/23 00:25:53 INFO util.GSet: Computing capacity for map INodeMap 14/07/23 00:25:53 INFO util.GSet: VM type = 64-bit 14/07/23 00:25:53 INFO util.GSet: 1.0% max memory = 3817799680 14/07/23 00:25:53 INFO util.GSet: capacity = 2^22 = 4194304 entries 14/07/23 00:25:53 INFO util.GSet: recommended=4194304, actual=4194304 14/07/23 00:25:53 INFO common.Storage: Image file of size 172 saved in 0 seconds. 14/07/23 00:25:53 INFO namenode.FSEditLog: closing edit log: position=4, editlog=c:\hdp\data\hdfs\nn\current\edits 14/07/23 00:25:53 INFO namenode.FSEditLog: close success: truncate to 4, editlog=c:\hdp\data\hdfs\nn\current\edits 14/07/23 00:25:53 INFO common.Storage: Storage directory c:\hdp\data\hdfs\nn has been successfully formatted. 14/07/23 00:25:53 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at HDP13-1NODE/10.0.2.15 ************************************************************/
I then ran the 'start all' script.
PS C:\hdp\hadoop> .\start_local_hdp_services.cmd starting namenode starting secondarynamenode starting datanode starting jobtracker starting historyserver starting tasktracker starting zkServer starting master starting regionserver starting hwi starting hiveserver starting hiveserver2 starting metastore starting derbyserver starting templeton starting oozieservice Sent all start commands. total services 16 running services 16 not yet running services 0 Failed_Start PS C:\hdp\hadoop>
Despite the weird "failed" message, the counts above aligned with what I saw on the Services console; all 16 of these started as shown below.
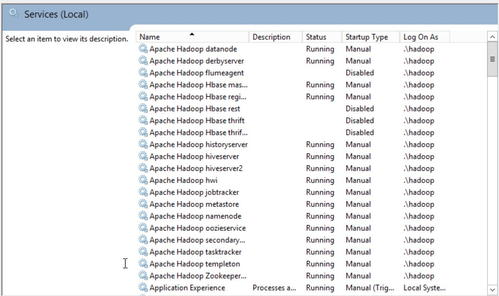
Smoke Tests
The smoke-tests failed pretty miserably as you see by checking out smokeTestFailures.txt, so I decided to take a slightly different tact to see if all is working well. I was able to pull up the trusty old UIs for JobTracker and NameNode on ports 50030 and 50070 (respectively) which was a good sign.
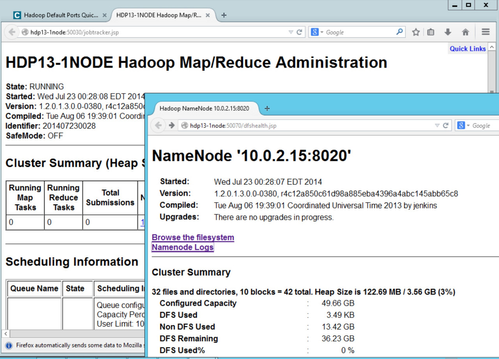
I added the "and then running something on it" to this blog post's title as this is where all the documentation I could find on the net stops. I didn't have luck finding a tutorial that actually did something other than declare it was installed. I'm now realizing I had more work cut out for me during this (already) late night on the computer.
To keep marching, I decided to see what would happen if I (logged in as "Administrator") tried to put some content into HDFS.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls / Found 2 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -mkdir /bogus PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls / Found 3 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 00:53 /bogus drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -put jobtracker.xml /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /bogus Found 1 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -cat /bogus/jobtracker.txt <service> <id>jobtracker</id> <name>jobtracker</name> <description>This service runs Isotope jobtracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-server -Xmx4096m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-jobtracker-HDP13-1NODE.log -Dhadoop.home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C: \hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop.policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\conf;C:\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3 .0.0-0380\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar ;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hado op-core.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1. 3.0.0-0380\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\ hadoop-tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org .apache.hadoop.mapred.JobTracker</arguments> </service>
Awesome; it worked! As expected, my new directory & file did show up with the correct username as the owner. Also as expected, this shows up in the NameNode UI.
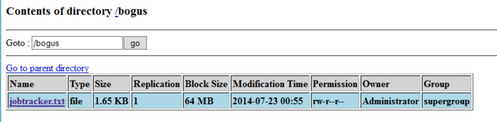
Typical (or not so?) User
As we shouldn't typically run things as a 'Administrator', I then logged into the Windows box as a user called 'lester' who happens to have administrator rights. I then did much of the same activities as done earlier (i.e. exploring a bit) with the FS Shell.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls / Found 3 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 00:55 /bogus drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /bogus Found 1 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -cat /bogus/jobtracker.txt <service> <id>jobtracker</id> <name>jobtracker</name> <description>This service runs Isotope jobtracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-server -Xmx4096m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-jobtracker-HDP13-1NODE.log -Dhadoop.home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C: \hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop.policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\conf;C:\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3 .0.0-0380\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar ;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hado op-core.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1. 3.0.0-0380\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\ hadoop-tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org .apache.hadoop.mapred.JobTracker</arguments> </service> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -put tasktracker.xml /bogus/tasktracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /bogus Found 2 items -rw-r--r-- 1 Administrator supergroup 1692 2014-07-23 00:55 /bogus/jobtracker.txt -rw-r--r-- 1 lester supergroup 1688 2014-07-23 01:20 /bogus/tasktracker.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -cat /bogus/tasktracker.txt <service> <id>tasktracker</id> <name>tasktracker</name> <description>This service runs Isotope tasktracker</description> <executable>C:\Software\Java\jdk1.6.0_31\bin\java</executable> <arguments>-Xmx512m -Dhadoop.log.dir=c:\hdp\logs\hadoop -Dhadoop.log.file=hadoop-tasktracker-HDP13-1NODE.log -Dhadoop .home.dir=C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380 -Dhadoop.root.logger=INFO,console,DRFA -Djava.library.path=;C:\hdp\had oop\hadoop-1.2.0.1.3.0.0-0380\lib\native\Windows_NT-amd64-64;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\native -Dhadoop .policy.file=hadoop-policy.xml -Dcom.sun.management.jmxremote -classpath C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\conf;C :\Software\Java\jdk1.6.0_31\lib\tools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-038 0\hadoop-ant-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-client-1.2.0.1.3.0.0-0380.jar;C:\hdp\ hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-core. jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-examples-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-03 80\hadoop-examples.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-minicluster-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\h adoop-1.2.0.1.3.0.0-0380\hadoop-test-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-test.jar;C:\h dp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-tools-1.2.0.1.3.0.0-0380.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\hadoop-t ools.jar;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\*;C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\lib\jsp-2.1\* org.apache. hadoop.mapred.TaskTracker</arguments> </service>
Bonus points to whomever tests out what happens when another user, who does not have local admin rights, does this same thing (i.e. what group would be aligned with the directories/files). For the purposes of my (initial) testing, and taking in account what time it is, let's move on as I am able to add files. We can also stop moving files into HDFS with the CLI since we're talking about folks on Windows who probably would prefer a GUI similar to the File Exploder. Red Gate's HDFS Explorer seems to do the trick (use the "Windows authentication" option and point to the hostname for the "Cluster address" during the setup).
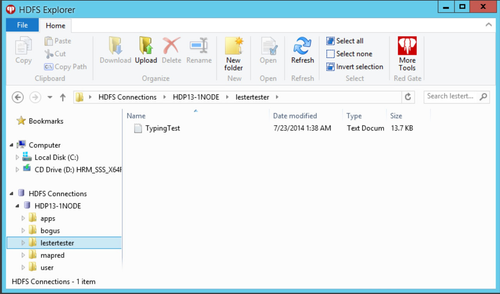
I actually expected to see the owner as 'lester' below instead of 'webuser', but again bonus points for running this down. For now, we can just march on as there doesn't seem to be any issue with the CLI tools utilizing these same files.
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls / Found 4 items drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /apps drwxr-xr-x - Administrator supergroup 0 2014-07-23 01:20 /bogus drwxr-xr-x - webuser supergroup 0 2014-07-23 01:39 /lestertester drwxr-xr-x - hadoop supergroup 0 2014-07-23 00:28 /mapred PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -ls /lestertester Found 1 items -rwxr-xr-x 1 webuser supergroup 14058 2014-07-23 01:39 /lestertester/TypingTest.txt PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop fs -rm /lestertester/TypingTest.txt Moved to trash: hdfs://HDP13-1NODE:8020/lestertester/TypingTest.txt
Tera Gen & Sort
Great, we can create content, so let's see if we can run Teragen and Terasort; and get myself tucked into bed!!
PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop jar ..\hadoop-examples.jar teragen 1000 /lestertester/sort1000/ input Generating 1000 using 2 maps with step of 500 14/07/23 02:13:34 INFO mapred.JobClient: Running job: job_201407230028_0001 14/07/23 02:13:35 INFO mapred.JobClient: map 0% reduce 0% 14/07/23 02:13:47 INFO mapred.JobClient: map 100% reduce 0% 14/07/23 02:13:48 INFO mapred.JobClient: Job complete: job_201407230028_0001 14/07/23 02:13:48 INFO mapred.JobClient: Counters: 19 14/07/23 02:13:48 INFO mapred.JobClient: Job Counters 14/07/23 02:13:48 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6644 14/07/23 02:13:48 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/07/23 02:13:48 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/07/23 02:13:48 INFO mapred.JobClient: Launched map tasks=2 14/07/23 02:13:48 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0 14/07/23 02:13:48 INFO mapred.JobClient: File Input Format Counters 14/07/23 02:13:48 INFO mapred.JobClient: Bytes Read=0 14/07/23 02:13:48 INFO mapred.JobClient: File Output Format Counters 14/07/23 02:13:48 INFO mapred.JobClient: Bytes Written=100000 14/07/23 02:13:48 INFO mapred.JobClient: FileSystemCounters 14/07/23 02:13:48 INFO mapred.JobClient: HDFS_BYTES_READ=164 14/07/23 02:13:48 INFO mapred.JobClient: FILE_BYTES_WRITTEN=113650 14/07/23 02:13:48 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=100000 14/07/23 02:13:48 INFO mapred.JobClient: Map-Reduce Framework 14/07/23 02:13:48 INFO mapred.JobClient: Map input records=1000 14/07/23 02:13:48 INFO mapred.JobClient: Physical memory (bytes) snapshot=177201152 14/07/23 02:13:48 INFO mapred.JobClient: Spilled Records=0 14/07/23 02:13:48 INFO mapred.JobClient: CPU time spent (ms)=390 14/07/23 02:13:48 INFO mapred.JobClient: Total committed heap usage (bytes)=257294336 14/07/23 02:13:48 INFO mapred.JobClient: Virtual memory (bytes) snapshot=385998848 14/07/23 02:13:48 INFO mapred.JobClient: Map input bytes=1000 14/07/23 02:13:48 INFO mapred.JobClient: Map output records=1000 14/07/23 02:13:48 INFO mapred.JobClient: SPLIT_RAW_BYTES=164 PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /lestertester/sort1000/input Found 3 items drwxr-xr-x - lester supergroup 0 2014-07-23 02:13 /lestertester/sort1000/input/_logs -rw-r--r-- 1 lester supergroup 50000 2014-07-23 02:13 /lestertester/sort1000/input/part-00000 -rw-r--r-- 1 lester supergroup 50000 2014-07-23 02:13 /lestertester/sort1000/input/part-00001 PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> ./hadoop jar ..\hadoop-examples.jar terasort /lestertester/sort1000/inpu t /lestertester/sort1000/output 14/07/23 02:16:44 INFO terasort.TeraSort: starting 14/07/23 02:16:44 INFO mapred.FileInputFormat: Total input paths to process : 2 14/07/23 02:16:44 INFO util.NativeCodeLoader: Loaded the native-hadoop library 14/07/23 02:16:44 WARN snappy.LoadSnappy: Snappy native library not loaded 14/07/23 02:16:44 WARN zlib.ZlibFactory: Failed to load/initialize native-zlib library 14/07/23 02:16:44 INFO compress.CodecPool: Got brand-new compressor Making 1 from 1000 records Step size is 1000.0 14/07/23 02:16:45 INFO mapred.FileInputFormat: Total input paths to process : 2 14/07/23 02:16:45 INFO mapred.JobClient: Running job: job_201407230028_0002 14/07/23 02:16:46 INFO mapred.JobClient: map 0% reduce 0% 14/07/23 02:16:51 INFO mapred.JobClient: map 100% reduce 0% 14/07/23 02:16:58 INFO mapred.JobClient: map 100% reduce 33% 14/07/23 02:16:59 INFO mapred.JobClient: map 100% reduce 100% 14/07/23 02:17:00 INFO mapred.JobClient: Job complete: job_201407230028_0002 14/07/23 02:17:00 INFO mapred.JobClient: Counters: 30 14/07/23 02:17:00 INFO mapred.JobClient: Job Counters 14/07/23 02:17:00 INFO mapred.JobClient: Launched reduce tasks=1 14/07/23 02:17:00 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=4891 14/07/23 02:17:00 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/07/23 02:17:00 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/07/23 02:17:00 INFO mapred.JobClient: Launched map tasks=2 14/07/23 02:17:00 INFO mapred.JobClient: Data-local map tasks=2 14/07/23 02:17:00 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8217 14/07/23 02:17:00 INFO mapred.JobClient: File Input Format Counters 14/07/23 02:17:00 INFO mapred.JobClient: Bytes Read=100000 14/07/23 02:17:00 INFO mapred.JobClient: File Output Format Counters 14/07/23 02:17:00 INFO mapred.JobClient: Bytes Written=100000 14/07/23 02:17:00 INFO mapred.JobClient: FileSystemCounters 14/07/23 02:17:00 INFO mapred.JobClient: FILE_BYTES_READ=102395 14/07/23 02:17:00 INFO mapred.JobClient: HDFS_BYTES_READ=100230 14/07/23 02:17:00 INFO mapred.JobClient: FILE_BYTES_WRITTEN=379949 14/07/23 02:17:00 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=100000 14/07/23 02:17:00 INFO mapred.JobClient: Map-Reduce Framework 14/07/23 02:17:00 INFO mapred.JobClient: Map output materialized bytes=102012 14/07/23 02:17:00 INFO mapred.JobClient: Map input records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Reduce shuffle bytes=102012 14/07/23 02:17:00 INFO mapred.JobClient: Spilled Records=2000 14/07/23 02:17:00 INFO mapred.JobClient: Map output bytes=100000 14/07/23 02:17:00 INFO mapred.JobClient: Total committed heap usage (bytes)=585302016 14/07/23 02:17:00 INFO mapred.JobClient: CPU time spent (ms)=1297 14/07/23 02:17:00 INFO mapred.JobClient: Map input bytes=100000 14/07/23 02:17:00 INFO mapred.JobClient: SPLIT_RAW_BYTES=230 14/07/23 02:17:00 INFO mapred.JobClient: Combine input records=0 14/07/23 02:17:00 INFO mapred.JobClient: Reduce input records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Reduce input groups=1000 14/07/23 02:17:00 INFO mapred.JobClient: Combine output records=0 14/07/23 02:17:00 INFO mapred.JobClient: Physical memory (bytes) snapshot=477831168 14/07/23 02:17:00 INFO mapred.JobClient: Reduce output records=1000 14/07/23 02:17:00 INFO mapred.JobClient: Virtual memory (bytes) snapshot=789450752 14/07/23 02:17:00 INFO mapred.JobClient: Map output records=1000 14/07/23 02:17:00 INFO terasort.TeraSort: done PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> PS C:\hdp\hadoop\hadoop-1.2.0.1.3.0.0-0380\bin> .\hadoop fs -ls /lestertester/sort1000/output Found 2 items drwxr-xr-x - lester supergroup 0 2014-07-23 02:16 /lestertester/sort1000/output/_logs -rw-r--r-- 1 lester supergroup 100000 2014-07-23 02:16 /lestertester/sort1000/output/part-00000
Awesome; it works! That's enough for now as it is VERY late and I have my "day job" to think about as well. ![]()