hadoop mount points (more art than science)
If you are reading this then the JBOD talk for Hadoop has probably already sunk in. Letting the worker nodes have as many spindles as possible is a cornerstone to this strategy whose overall goal is to spread out the I/O and to ensure data locality. How many spindles per node? Well, there are slight differences in opinion here and I've previously shared my thoughts in my hadoop worker node configuration recommendations (1-2-10) blog posting. But, before we start talking about different node stereotypes let's focus on common file systems for all nodes (master, workers, edge, perimeter, management, etc) that will have Hadoop bits laid down on then move into the differences for each node type.
DISCLAIMER
The recommendations presented in this blog are MINE and not necessarily that of my current employer (Hortonworks) or aligned with other Hadoop distribution vendors or platform architecture experts. That said, I think this will make a lot of sense and I welcome comments & questions at the bottom of the posting.
| I am most familiar with HDP (which is 100% Apache open-source), so I'm including the contents of HDP File Locations here as a quick primer. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
As the picture below dictates, there are major areas of the logical directory tree where Hadoop persists bits, config, logs and, of course, data. The following table shows what directories are used by default when installing Hortonworks Data Platform.
|
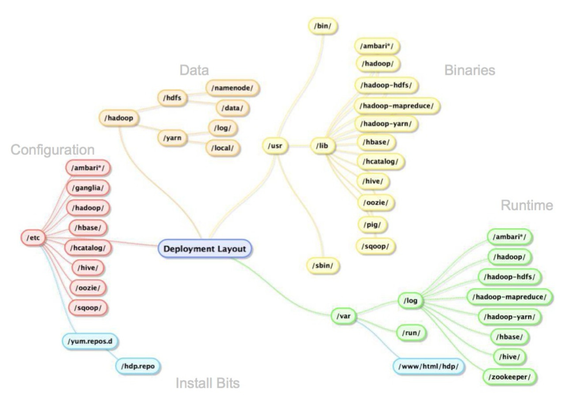
General Background
Hardware Selection
During most of my Hadoop consulting engagements I've seen a trend to simply buy the same hardware for masters and workers (and sometimes edge nodes). It is easy to understand why companies new to Hadoop do this. It seems to boil down to the fact they know how to create "t-shirt sizes" for common usages such as application servers and database servers, but neither of these configurations are optimal for Hadoop worker nodes. Teams then spend a good amount of time with the hardware procurement team defining a box that ends up looking something like 12 2TB drives, dual 8 core processors, and 128GB of RAM. Well... that or they give-up and start in the cloud!
Once the internal hardware ordering team "gets it" for the workers, the next conversation starts about how to configure the masters and usually heads start turning. About this time, most folks just go with the strategy of ordering the same hardware for the masters to keep the procurement process rolling. At first this bothered me a bit, but now I've realized this works out nicely as you'll see later when we talk about file system mount points for masters.
So... for this blog posting we will run with the assumption that we have 12 separate 2TB disks along with two additional smaller (roughly 500GB) drives in ALL machines.
OS-Level Partitions
This is surely a touchy one as I've met many Linux systems administrators and while there is a lot of consistency, there is still a bit of "special sauce" that gets smothered on top; especially when we talk about the base OS partition. Generally, I try to stay out of these religious arguments. Besides, many teams have already made decisions on how they lay down the OS. Of the four main areas that Hadoop distributions need disk space for (i.e. bits, config, logs and data), I usually subscribe to the model of letting the bits, config and logs, as identified above, be persisted in their default locations. As there are many independently running Hadoop services, it is easy to imagine big requirements on disk storage for logging. If the Linux administrators have a strategy for this, then great, but it does need to be thought about.
One strategy I've seen well is to have a separate mount point (and underlying disk) devoted to /var/log for all components, not just Hadoop ones, to log to. I'll offer some suggestions that are varied by node stereotypes below, but if there was one area I'd look to my system administrators to fully support it surely is in this space.
Node Stereotypes
The rest of this blog posting will be to offer up my suggestions around file system mount points based on the primary node stereotypes. In addition to the thoughts on the root file system and an appropriate mechanism for /var/log, I suggest ALL nodes have a /hadoop mount point as most components need a centralized directory to base additional configuration from.
Master Nodes
For masters (this would include "management" nodes such as Ambari and "perimeter" nodes such as Knox) we need to make the boxes are resilient as possible. For that, and given the smaller number of node counts used for this stereotype, a heavy dose of drive mirroring seems to be appropriate.
| Mount Point | Which Disks & How Configured | Details |
|---|---|---|
/ | Use both of the 500GB disks in a mirrored fashion | Ensure the OS can run even is a disk fails |
/var/log | Use two of the 2TB disks in a mirrored fashion | Definitely want admins' buy-in on this strategy, but just trying to keep the boxes running at all costs and to not allow the size of the logs to be a runtime concern |
/hadoop | Use two of the 2TB disks in a mirrored fashion | |
/master/data/1 | Use two of the 2TB disks in a mirrored fashion | These will be the mount points used by the NameNode and JournalNode processes |
/master/data/2 | Use two of the 2TB disks in a mirrored fashion | Also for NN & JN as even with HA NN setup, we want the NN processes to write their fsimage files to more than one (logical) disk – hey, the bunker scene can happen!! I even strongly recommend soft mounting a NFS directory and periodically making a backup of the NN's fsimage and JN's edits files; this may seem like overkill, but ensure your operational procedures are rock solid & tested when it comes to the NameNode and its fsimage/edits files recovery |
/master/zk | Use two of the 2TB disks in a mirrored fashion | As more and more components start leveraging ZooKeeper, and with the intensity that HBase communicates with it, it makes solid sense to allow ZK to have its own disks |
This would leave two additional 2TB drives in the chassis which could allow some flexibility in system restoration should one of the other drives fail. One might also think that only the appropriate /master/XXX file systems should be mounted on the "correct" master nodes, but as a robust set of hadoop master nodes (it is hard to swing it with two machines) indicates, you really will not have an unbounded number of master nodes and it makes more sense to build out all universally so that one could adapt to system failures and/or additional node expansions by allowing master component reassignments to be easier with all appropriate file systems being on all master nodes.
Worker Nodes
The worker nodes have a different restoration policy than the masters and should be setup to maximize storage instead of minimizing the possibility of failure. Taking this into account, I prescribe the following based on the hardware described earlier.
| Mount Point | Which Disks & How Configured | Details |
|---|---|---|
/ | Use one of the 500GB disks | |
/var/log | Use the other 500GB disk | Again, definitely want admins' buy-in on this strategy |
/hadoop | Use one of the 2TB disks | |
| Individually mount the remaining 11 2TB disks | The heart of the Just a Bunch Of Disks (JBOD) strategy |
The real gotcha above is consuming a full "big disk" just for /hadoop. An alternative is to partition it into two entities that would surface as /hadoop and one of the /worker/NN mount points.
Edge Nodes
The edge, and ingestion, nodes are focused on ensuring there is plenty of storage for transient data. Generally speaking, these are replaceable nodes and the data they house should be able to be recreated from either the source or from HDFS.
| Mount Point | Which Disks & How Configured | Details |
|---|---|---|
/ | Use one of the 500GB disks | |
/var/log | Use the other 500GB disk | |
/hadoop | Use one of the 2TB disks | Maintain consistency with the other node stereotypes |
| varies (likely the root of home directories) | Use one, to many, of the remaining (or available) disks in a logical volume that provides some level of protection from a drive failure | It is very likely that a much less resource rich machine than previously described will be used for the edge nodes and thus, you should use whatever drives are available to build the best-case storage option for this transient data requirement |
Especially when there are multiple edge nodes and the expectation is for a user (or process) to arbitrarily log into any of them and have a consistent home directory, other alternatives, such as a network mounted home directory may be appropriate.
Parting Thoughts
With all of the varying opinions, experiences and self-imposed standards at play, it is very likely that the individual mount points used for one enterprise's Hadoop cluster will be identical to that from another company. Fortunately, what matters most is understanding what the technology itself is doing, which components will be most utilized and validating your assumptions to ensure you are being data-driven (not emotionally-driven) when making these important decisions for your cluster. I'm hopeful this information helped a bit.
Happy Hadooping!