If you are reading this then the JBOD talk for Hadoop has probably already sunk in. Letting the worker nodes have as many spindles as possible is a cornerstone to this strategy whose overall goal is to spread out the I/O and to ensure data locality. How many spindles per node? Well, there are slight differences in opinion here and I've previously shared my thoughts in my hadoop worker node configuration recommendations (1-2-10) blog posting. But, before we start talking about different node stereotypes let's focus on common file systems for all nodes (master, workers, edge, perimeter, management, etc) that will have Hadoop bits laid down on then move into the differences for each node type.
DISCLAIMER
The recommendations presented in this blog are MINE and not necessarily that of my current employer (Hortonworks) or aligned with other Hadoop distribution vendors or platform architecture experts. That said, I think this will make a lot of sense and I welcome comments & questions at the bottom of the posting.
| I'm most familiar with HDP (which is 100% Apache open-source), so I'm including the contents of HDP File Locations here as a quick primer. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
As the picture below dictates, there are major areas of the logical directory tree where Hadoop persists bits, config, logs and, of course, data. The following table shows what directories are used by default when installing Hortonworks Data Platform.
|
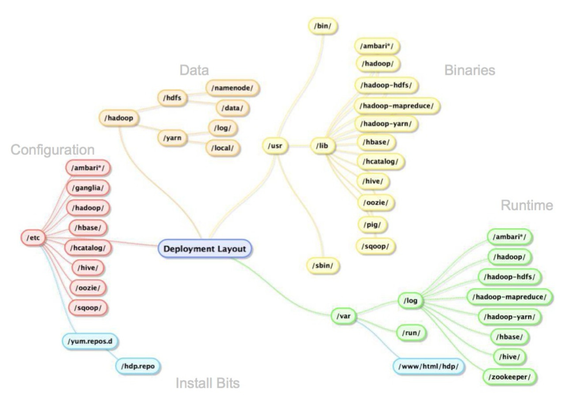
General Hardware
During most of my Hadoop consulting engagements I've seen a trend to simply buy the same hardware for masters and workers (and sometimes edge nodes). It is easy to understand why companies new to Hadoop do this. It seems to boil down to the fact they know how to create "t-shirt sizes" for common usages such as application servers and database servers, but neither of these configurations are optimal for Hadoop worker nodes. Teams then spend a good amount of time with the hardware procurement team defining a box that ends up looking something like 12 2TB drives, dual 8 core processors, and 128GB of RAM. Well... that or they give-up and start in the cloud!
Once the internal hardware ordering team "gets it" for the workers, the next conversation starts about how to configure the masters and usually heads start turning. About this time, most folks just go with the strategy of ordering the same hardware for the masters to keep the procurement process rolling. At first this bothered me a bit, but now I've realized this works out nicely as you'll see later when we talk about file system mount points for masters.
So... for this blog posting we will run with the assumption that we have 12 separate 2TB disks along with two additional smaller (roughly 500GB) drives in ALL machines.
OS-Level Partitions
This is surely a touchy one as I've met many Linux systems administrators and while there is a lot of consistency, there is still a bit of "special sauce" that gets smothered on top; especially when we touch about base OS partition.